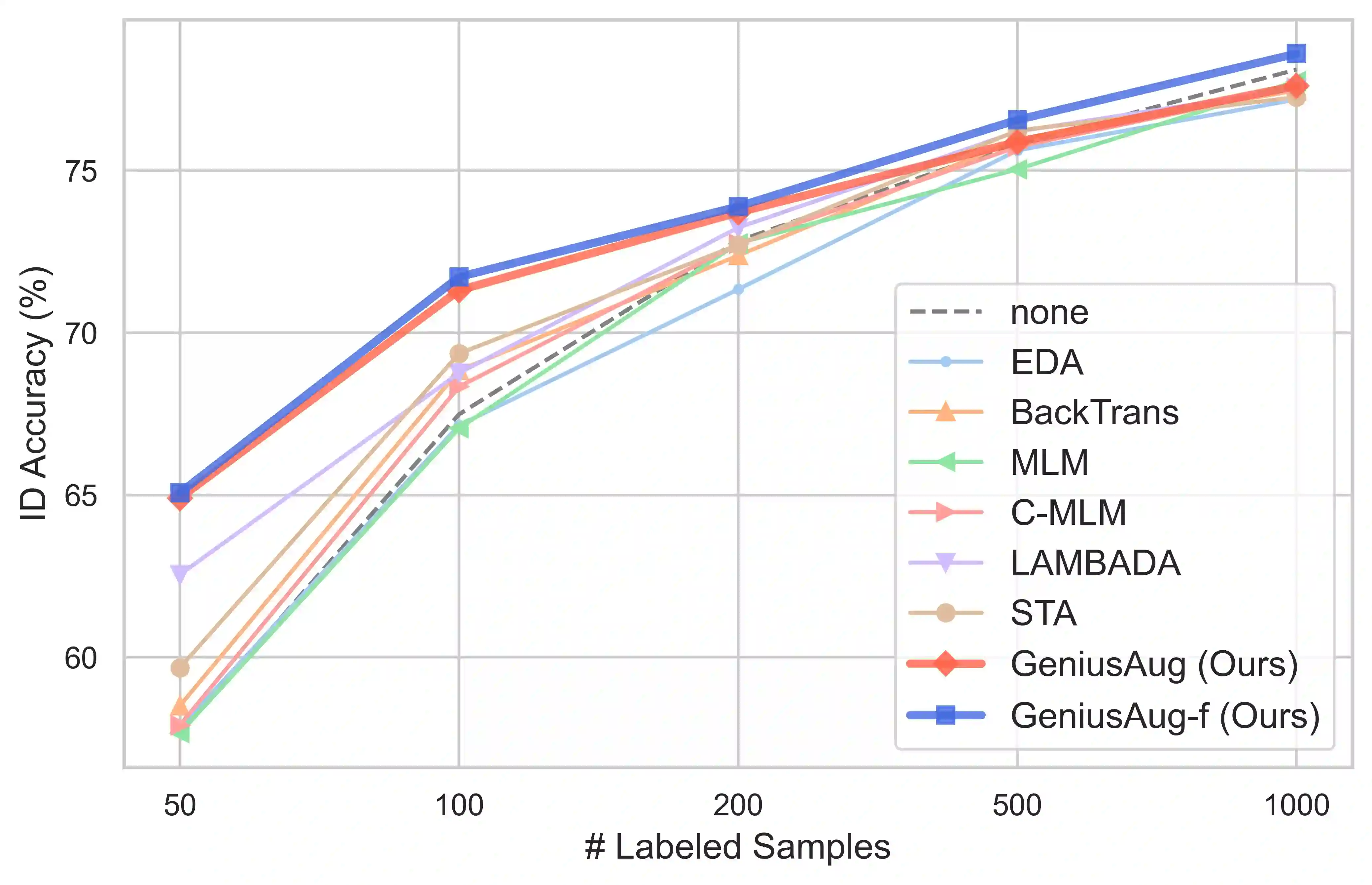
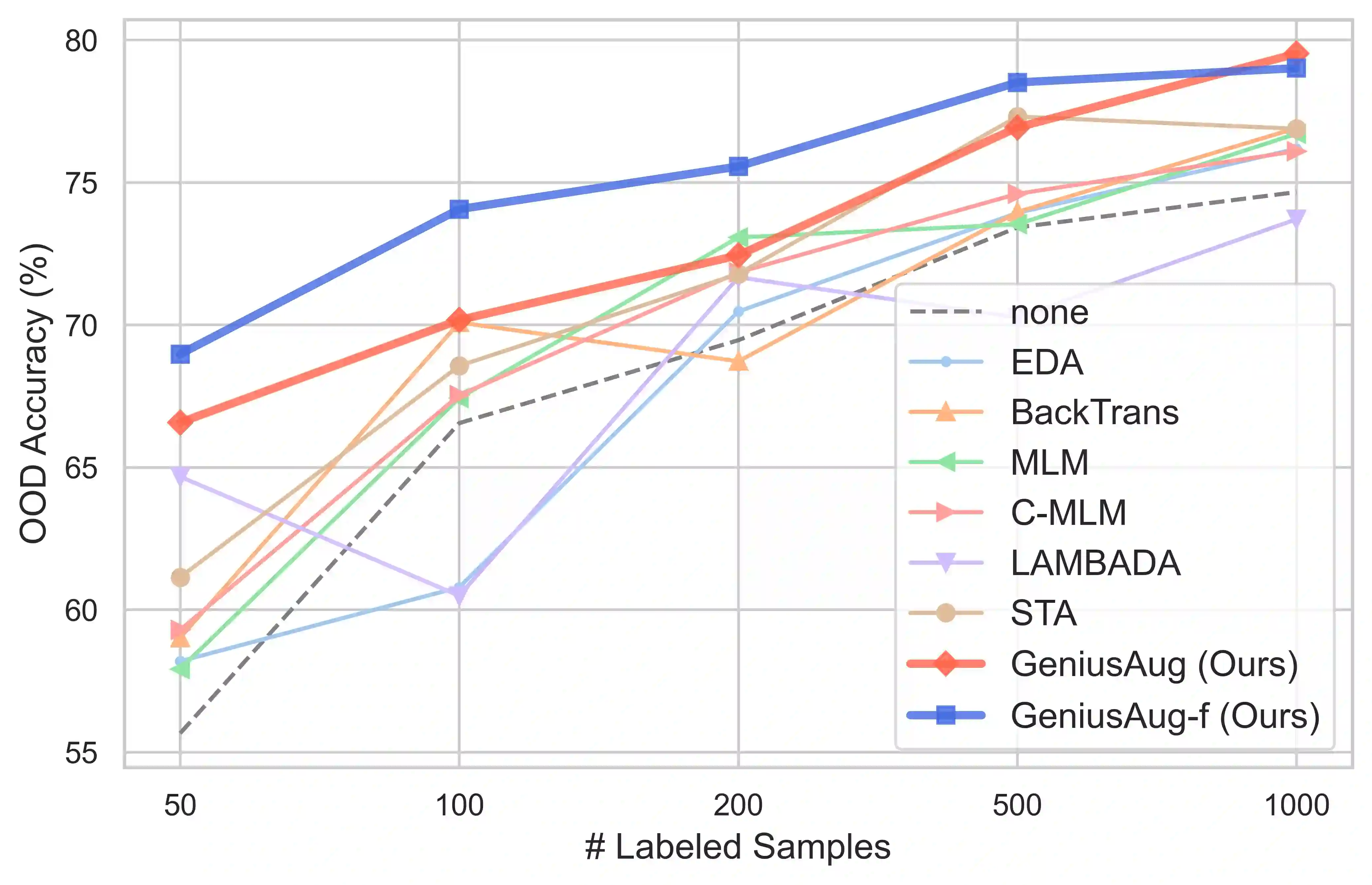
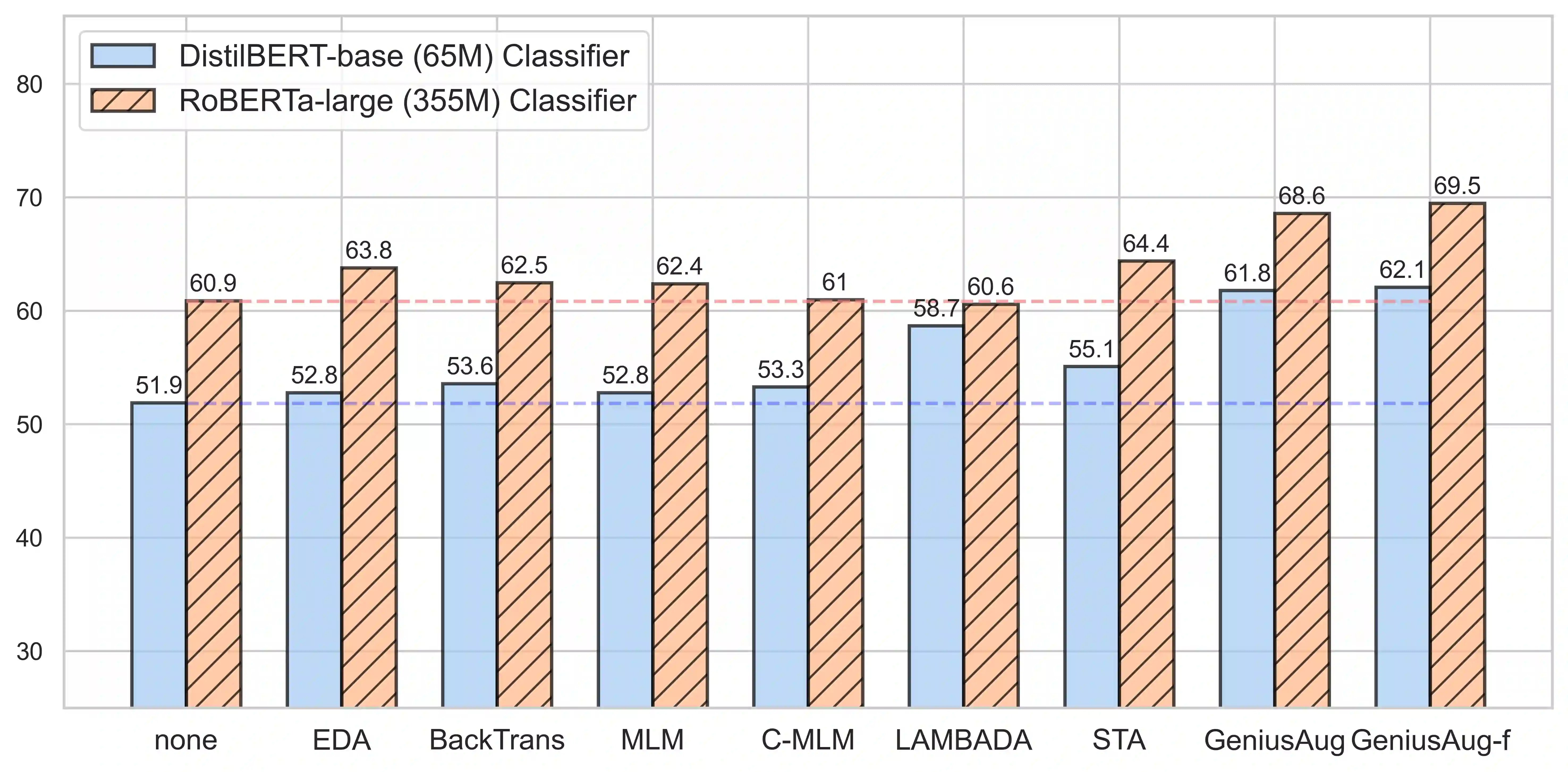
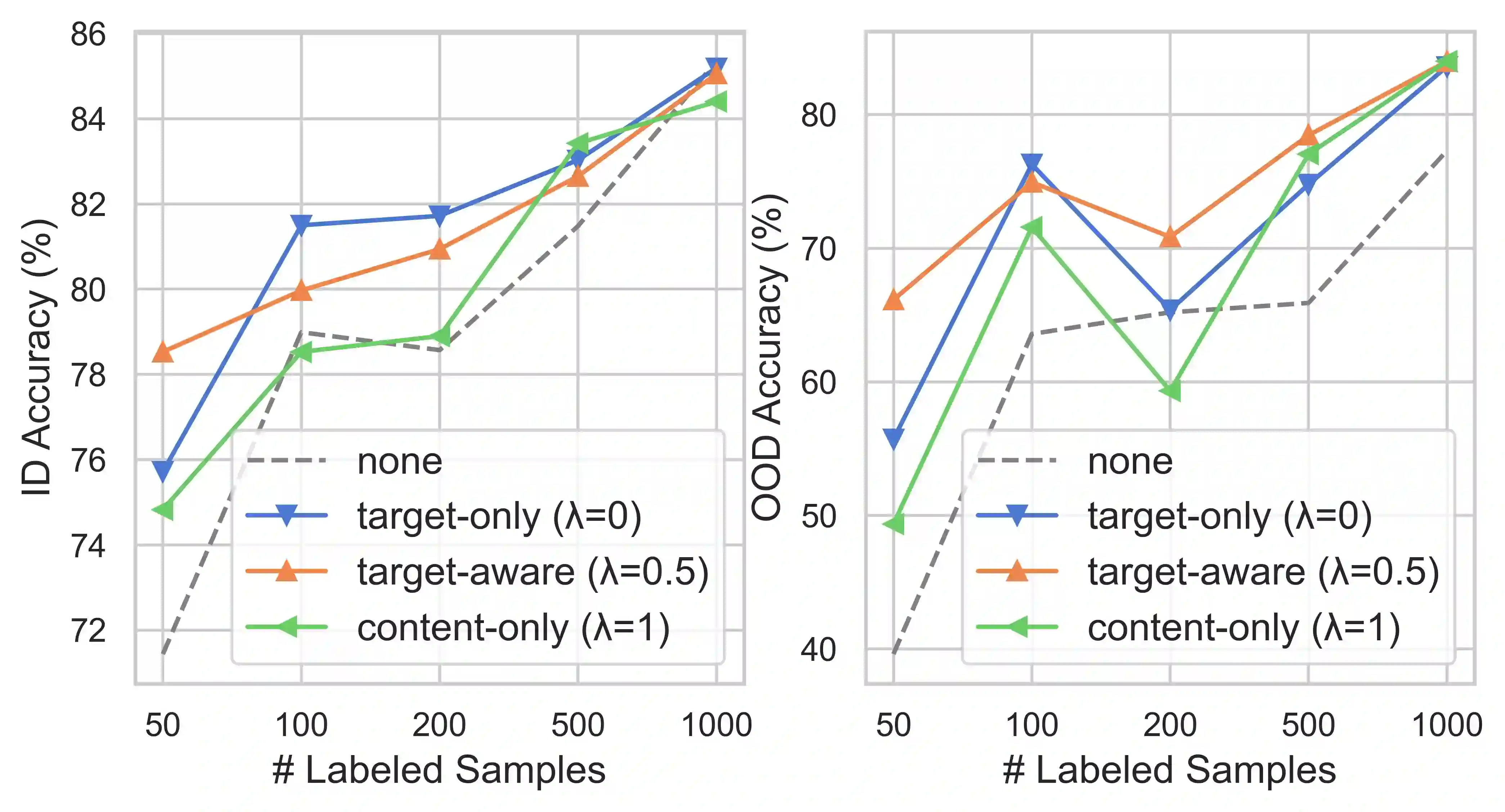
We introduce GENIUS: a conditional text generation model using sketches as input, which can fill in the missing contexts for a given sketch (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large-scale textual corpus with a novel reconstruction from sketch objective using an extreme and selective masking strategy, enabling it to generate diverse and high-quality texts given sketches. Comparison with other competitive conditional language models (CLMs) reveals the superiority of GENIUS's text generation quality. We further show that GENIUS can be used as a strong and ready-to-use data augmentation tool for various natural language processing (NLP) tasks. Most existing textual data augmentation methods are either too conservative, by making small changes to the original text, or too aggressive, by creating entirely new samples. With GENIUS, we propose GeniusAug, which first extracts the target-aware sketches from the original training set and then generates new samples based on the sketches. Empirical experiments on 6 text classification datasets show that GeniusAug significantly improves the models' performance in both in-distribution (ID) and out-of-distribution (OOD) settings. We also demonstrate the effectiveness of GeniusAug on named entity recognition (NER) and machine reading comprehension (MRC) tasks. (Code and models are publicly available at https://github.com/microsoft/SCGLab and https://github.com/beyondguo/genius)
翻译:我们引入了GENIUS:一种有条件的文本生成模型,使用素描作为输入,可以填补某个素描(由文字、短语或文字组成的关键信息,由遮罩符号混合起来)缺失的空隙背景。 GENIUS在大规模文本堆中先接受过培训,在草图目标上使用极端和选择性的掩码战略进行新的重建,使之从草图目标中重建出多种高质量的文本。与其他有竞争力的有条件语言模型(CLMS)比较,揭示了GENNIUS文本生成质量的优越性。我们进一步表明,GENNIUS可以用作各种自然语言处理(NLP)任务的强大和随时可用的数据增强工具。大多数现有的文本数据增强方法要么过于保守,对原始文本稍作改动,要么过于积极,使其从草图中产生全新的版本。我们建议GeniusAug,首先从最初的培训集中提取目标-觉醒目的素描图,然后根据草图生成新的样本。我们进一步表明,在6个文本分类数据处理/流化(GeniusA)中,Genius-Arucial-A(Ogius)在公开的模型中大大改进了Gen-Oius-Omab-Oni-Omab-Odrodu)。