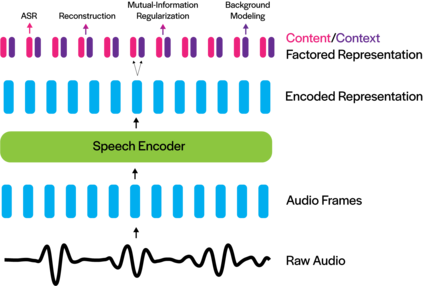
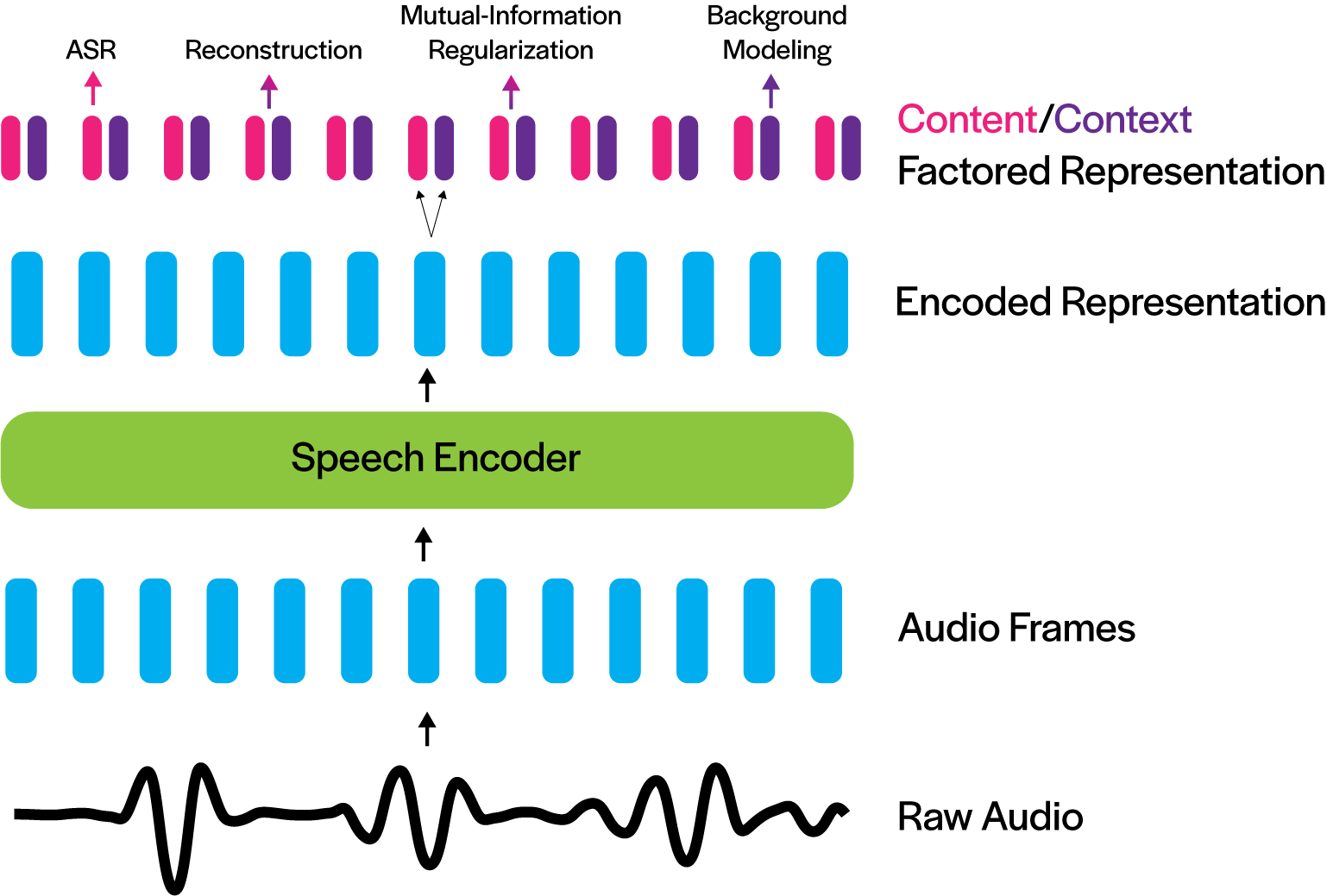
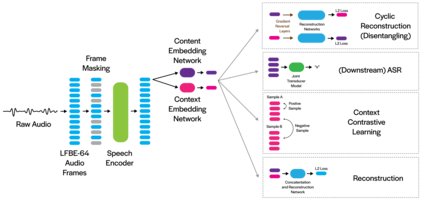Deep neural networks have largely demonstrated their ability to perform automated speech recognition (ASR) by extracting meaningful features from input audio frames. Such features, however, may consist not only of information about the spoken language content, but also may contain information about unnecessary contexts such as background noise and sounds or speaker identity, accent, or protected attributes. Such information can directly harm generalization performance, by introducing spurious correlations between the spoken words and the context in which such words were spoken. In this work, we introduce an unsupervised, encoder-agnostic method for factoring speech-encoder representations into explicit content-encoding representations and spurious context-encoding representations. By doing so, we demonstrate improved performance on standard ASR benchmarks, as well as improved performance in both real-world and artificially noisy ASR scenarios.
翻译:深神经网络通过从输入的音频框中提取有意义的特征,大体上表明它们有能力进行自动语音识别(ASR),但是,这些特征可能不仅包括口头语言内容的信息,而且可能包含关于不必要环境的信息,例如背景噪音和声音或声音或声音身份、口音或受保护属性等信息;这类信息可能直接损害一般化的性能,在口头语言和这些语言的发音背景之间引入虚假的关联性;在这项工作中,我们采用了一种未经监督的、加密的计算方法,将语音编码代表纳入明确的内容编码表述和虚假的背景编码表述中;通过这样做,我们展示了在标准ASR基准上的改进性能,以及在现实世界和人为吵闹的ASR情景中提高性能。