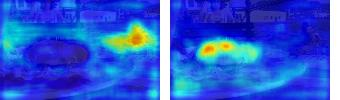
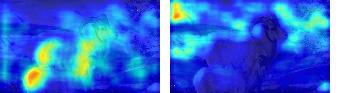
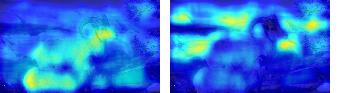
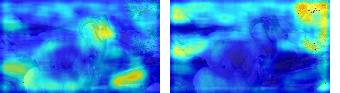
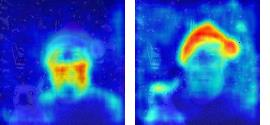
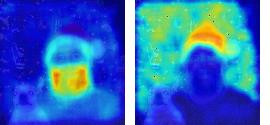
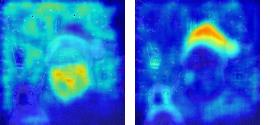
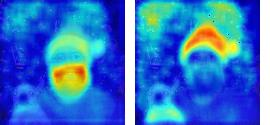
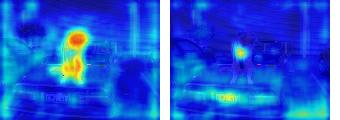
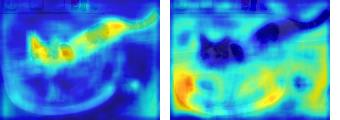
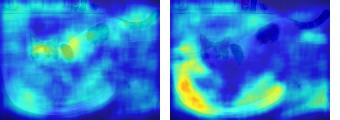
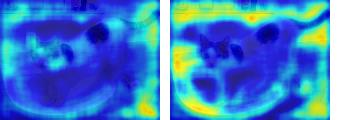
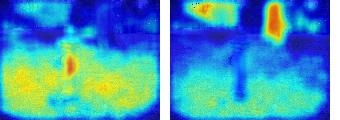
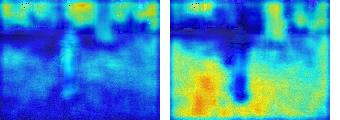
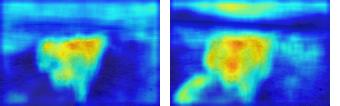
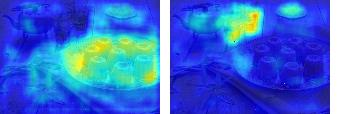
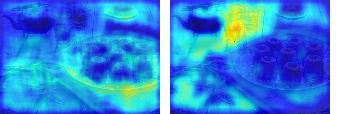
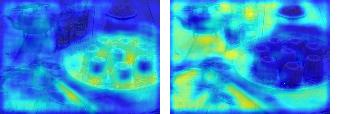
This paper presents a simple yet effective framework MaskCLIP, which incorporates a newly proposed masked self-distillation into contrastive language-image pretraining. The core idea of masked self-distillation is to distill representation from a full image to the representation predicted from a masked image. Such incorporation enjoys two vital benefits. First, masked self-distillation targets local patch representation learning, which is complementary to vision-language contrastive focusing on text-related representation.Second, masked self-distillation is also consistent with vision-language contrastive from the perspective of training objective as both utilize the visual encoder for feature aligning, and thus is able to learn local semantics getting indirect supervision from the language. We provide specially designed experiments with a comprehensive analysis to validate the two benefits. Empirically, we show that MaskCLIP, when applied to various challenging downstream tasks, achieves superior results in linear probing, finetuning as well as the zero-shot performance with the guidance of the language encoder.
翻译:本文提出了一个简单而有效的框架 MaskCLIP, 将新提出的蒙面自我蒸馏纳入对比性语言图像培训前阶段。 蒙面自我蒸馏的核心理念是将图像从完整的图像蒸馏到蒙面图像预测的表达方式。 这种整合具有两个重要好处。 首先, 蒙面自我蒸馏目标是局部补丁代表制学习, 这与注重文本代表方式的视觉语言对比性学习是相辅相成的。 其次, 蒙面自我蒸馏也与从培训目标角度的愿景语言对比一致,因为培训目标既利用视觉编码器进行功能组合,也能够学习本地语义学,从语言中间接监督。 我们提供专门设计的实验,通过全面分析来验证两种好处。 我们随机地表明, MaskCLIP 在应用于各种具有挑战性的下游任务时,在线性勘测、微调以及根据语言编码器的指导零发性表现方面,取得了优异的结果。