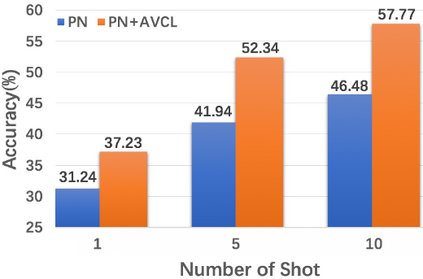
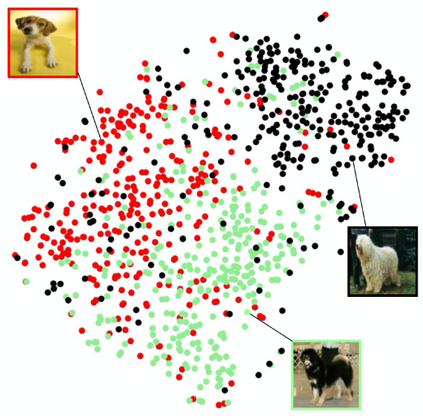
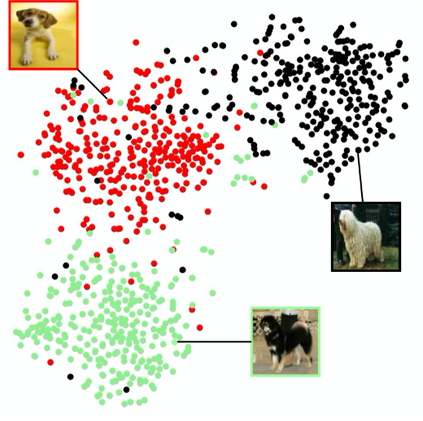
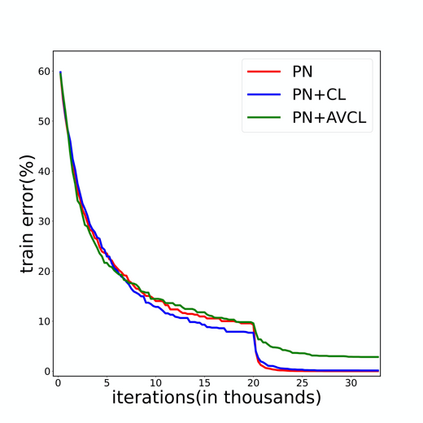
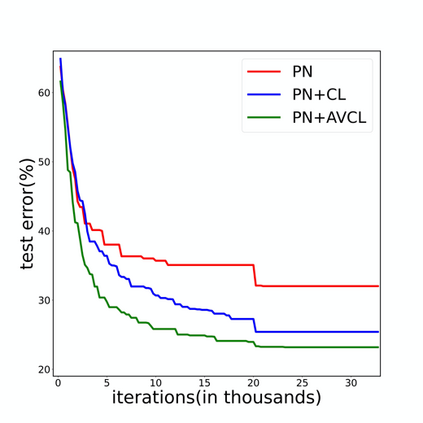
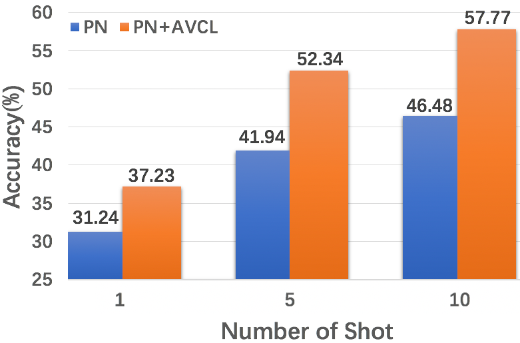
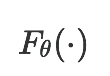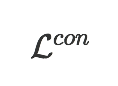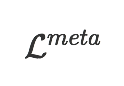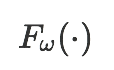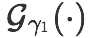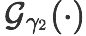The goal of few-shot classification is to classify new categories with few labeled examples within each class. Nowadays, the excellent performance in handling few-shot classification problems is shown by metric-based meta-learning methods. However, it is very hard for previous methods to discriminate the fine-grained sub-categories in the embedding space without fine-grained labels. This may lead to unsatisfactory generalization to fine-grained subcategories, and thus affects model interpretation. To tackle this problem, we introduce the contrastive loss into few-shot classification for learning latent fine-grained structure in the embedding space. Furthermore, to overcome the drawbacks of random image transformation used in current contrastive learning in producing noisy and inaccurate image pairs (i.e., views), we develop a learning-to-learn algorithm to automatically generate different views of the same image. Extensive experiments on standard few-shot learning benchmarks demonstrate the superiority of our method.
翻译:短片分类的目的是将新类别分类,每类中贴上很少标签的例子。 如今,处理短片分类问题的出色表现通过基于标准的元化学习方法表现出来。 但是,对于以往的方法来说,很难区分嵌入空间中未贴上细片标签的细片子类别。 这可能会导致对细片子类别进行不令人满意的概括化,从而影响模型解释。 为了解决这个问题,我们把对比性损失引入了微片分类,用于学习嵌入空间中的潜在细片结构。此外,为了克服当前对比性学习中用于制作噪音和不准确图像配对的随机图像转换的缺陷(例如,视图),我们开发了一种学习到阅读的算法,以自动生成对同一图像的不同观点。 标准的微片学习基准的大规模实验显示了我们方法的优势。