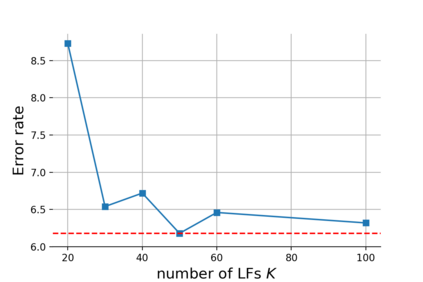
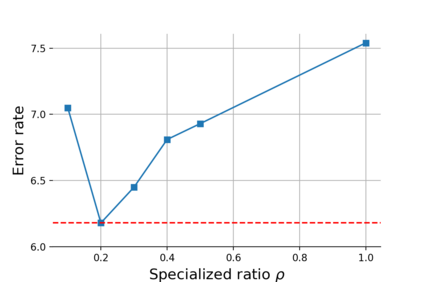
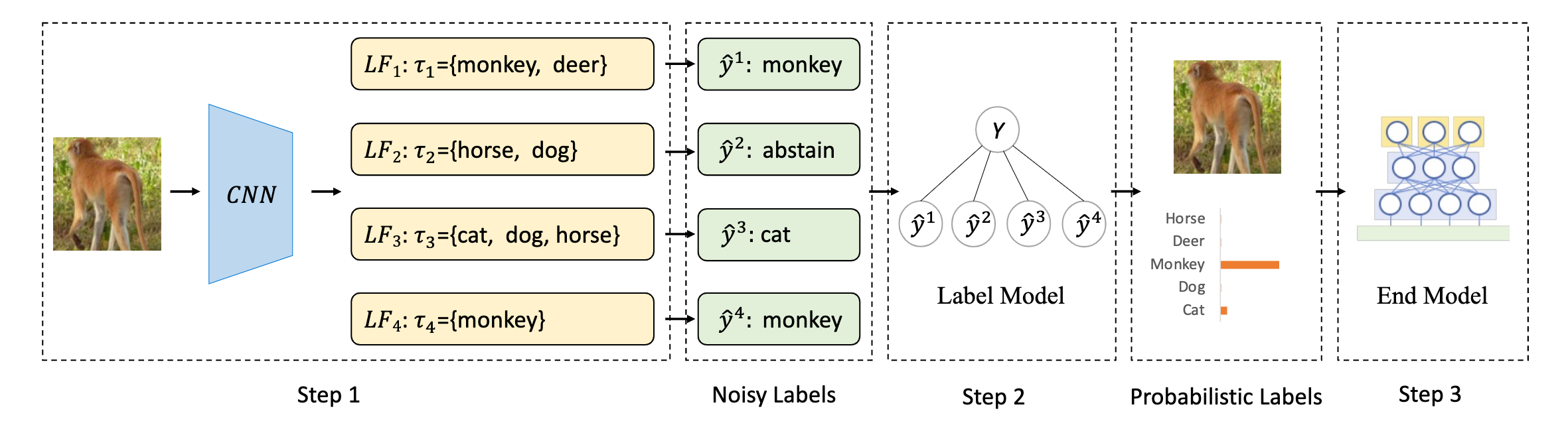
The scarcity of labeled data is a critical obstacle to deep learning. Semi-supervised learning (SSL) provides a promising way to leverage unlabeled data by pseudo labels. However, when the size of labeled data is very small (say a few labeled samples per class), SSL performs poorly and unstably, possibly due to the low quality of learned pseudo labels. In this paper, we propose a new SSL method called DP-SSL that adopts an innovative data programming (DP) scheme to generate probabilistic labels for unlabeled data. Different from existing DP methods that rely on human experts to provide initial labeling functions (LFs), we develop a multiple-choice learning~(MCL) based approach to automatically generate LFs from scratch in SSL style. With the noisy labels produced by the LFs, we design a label model to resolve the conflict and overlap among the noisy labels, and finally infer probabilistic labels for unlabeled samples. Extensive experiments on four standard SSL benchmarks show that DP-SSL can provide reliable labels for unlabeled data and achieve better classification performance on test sets than existing SSL methods, especially when only a small number of labeled samples are available. Concretely, for CIFAR-10 with only 40 labeled samples, DP-SSL achieves 93.82% annotation accuracy on unlabeled data and 93.46% classification accuracy on test data, which are higher than the SOTA results.
翻译:标签数据稀缺是深层学习的关键障碍。 半监督学习( SSL) 提供了一种有希望的方法, 以假标签来利用未标签数据。 但是, 当标签数据的规模很小( 说每类几个标签样本) 时, SSL 表现不佳且不可靠, 可能是因为学习的假标签质量低。 在本文中, 我们提出一种新的 SSL 方法, 称为 DP- SSL, 采用创新的数据编程( DP) 办法, 为未标签数据生成概率标签标签标签。 与现有的DP- SSL 方法不同, 后者依靠人类专家提供初始标签功能( LF), 我们开发了基于多选方法学习~( MCL) 的方法, 以便从 SSL 风格的抓痕中自动生成LF( MI) 。 由于Ls 生成的杂音标签质量, 我们设计了一个标签模型, 以解决噪音标签标签标签之间的矛盾和重叠, 最后推导无标签样本的概率标签标签。 在四个标准标准 SSL 基准上的广泛实验显示, DP- SSL 只能提供未标签的不可靠的标签标签标签的准确性标签标签标签, 数据, 在40 标定数据样本上, 中, 的标定的标定数据样本中, 的精确的标定的标签只有比为40 。