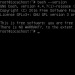
Given recent advancements of Large Language Models (LLMs), code generation tasks attract immense attention for wide application in different domains. In an effort to evaluate and select a best model to automatically remediate system incidents discovered by Application Performance Monitoring (APM) platforms, it is crucial to verify if the generated code is syntactically and semantically correct, and whether it can be executed correctly as intended. However, current methods for evaluating the quality of code generated by LLMs heavily rely on surface form similarity metrics (e.g. BLEU, ROUGE, and exact/partial match) which have numerous limitations. In contrast, execution based evaluation focuses more on code functionality and does not constrain the code generation to any fixed solution. Nevertheless, designing and implementing such execution-based evaluation platform is not a trivial task. There are several works creating execution-based evaluation platforms for popular programming languages such as SQL, Python, Java, but limited or no attempts for scripting languages such as Bash and PowerShell. In this paper, we present the first execution-based evaluation platform in which we created three test suites (total 125 handcrafted test cases) to evaluate Bash (both single-line commands and multiple-line scripts) and PowerShell codes generated by LLMs. We benchmark seven closed and open-source LLMs using our platform with different techniques (zero-shot vs. few-shot learning).
翻译:暂无翻译