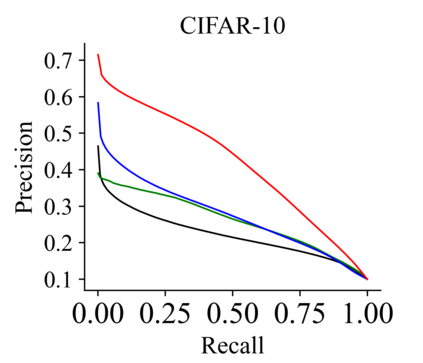
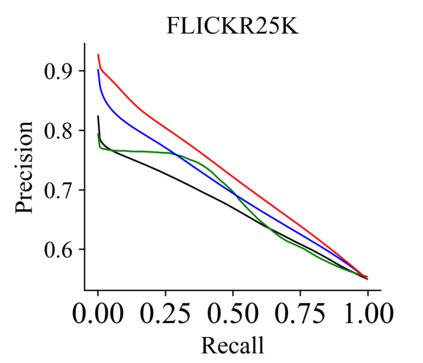
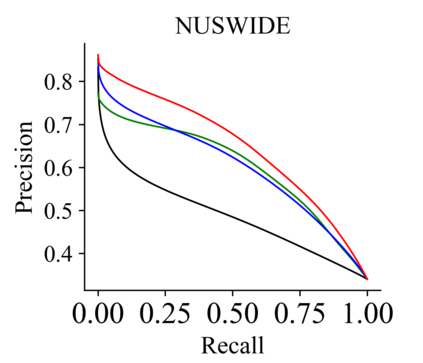
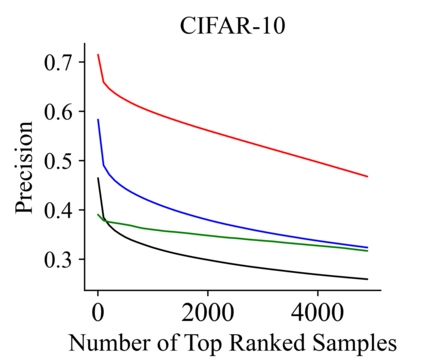
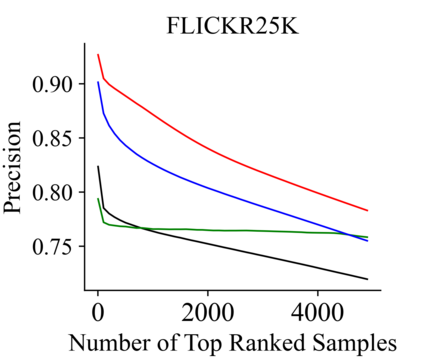
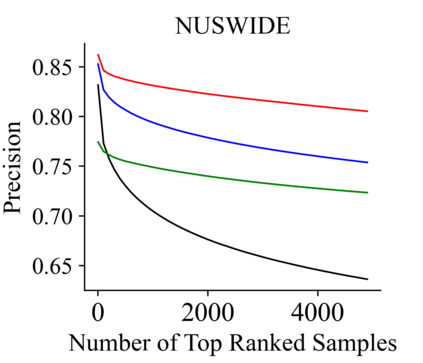
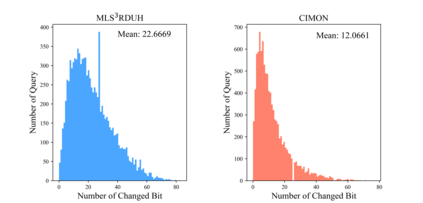
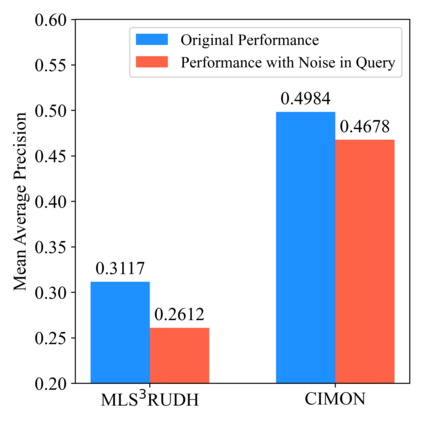
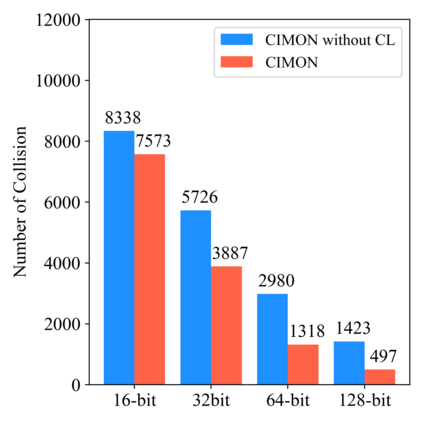
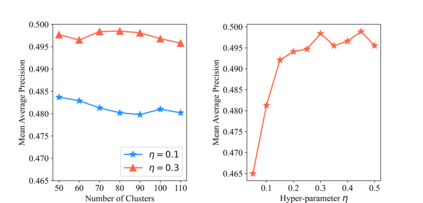
Recently, hashing is widely-used in approximate nearest neighbor search for its storage and computational efficiency. Due to the lack of labeled data in practice, many studies focus on unsupervised hashing. Most of the unsupervised hashing methods learn to map images into semantic similarity-preserving hash codes by constructing local semantic similarity structure from the pre-trained model as guiding information, i.e., treating each point pair similar if their distance is small in feature space. However, due to the inefficient representation ability of the pre-trained model, many false positives and negatives in local semantic similarity will be introduced and lead to error propagation during hash code learning. Moreover, most of hashing methods ignore the basic characteristics of hash codes such as collisions, which will cause instability of hash codes to disturbance. In this paper, we propose a new method named Comprehensive sImilarity Mining and cOnsistency learNing (CIMON). First, we use global constraint learning and similarity statistical distribution to obtain reliable and smooth guidance. Second, image augmentation and consistency learning will be introduced to explore both semantic and contrastive consistency to derive robust hash codes with fewer collisions. Extensive experiments on several benchmark datasets show that the proposed method consistently outperforms a wide range of state-of-the-art methods in both retrieval performance and robustness.
翻译:最近,散列被广泛用于近邻近邻搜寻其储存和计算效率的近距离搜索中。但由于实践中缺少标签数据,许多研究将侧重于未经监督的散列。大多数未经监督的散列方法将图像映射成语义相似性保存散列代码,方法是从事先培训的模型中构建本地语义相似结构,作为指导信息,即,如果在特征空间距离小,则将每对点对相类似的处理。然而,由于预先培训的模式的代表性能力低,许多地方语义相似性中的假正反正和负正将引入,导致在散列代码学习期间传播错误。此外,大多数散列方法忽视了诸如碰撞等散列代码的基本特征,从而导致散列代码的不稳定性干扰。在本文中,我们提出了一种名为“全面智能采矿”和“可识别性里arning(CIMON)”的新方法。首先,我们使用全球约束性学习和类似性统计分布方法来获得可靠和平稳的指导。第二,图像增强性和一致性方法的传播方法会忽略诸如碰撞碰撞等基本标准,从而探索各种稳定性数据的一致性和一致性的比较。提议。在稳定性标准上,将逐渐地试验将展示。