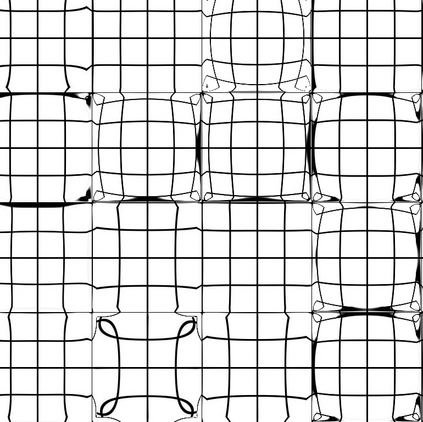
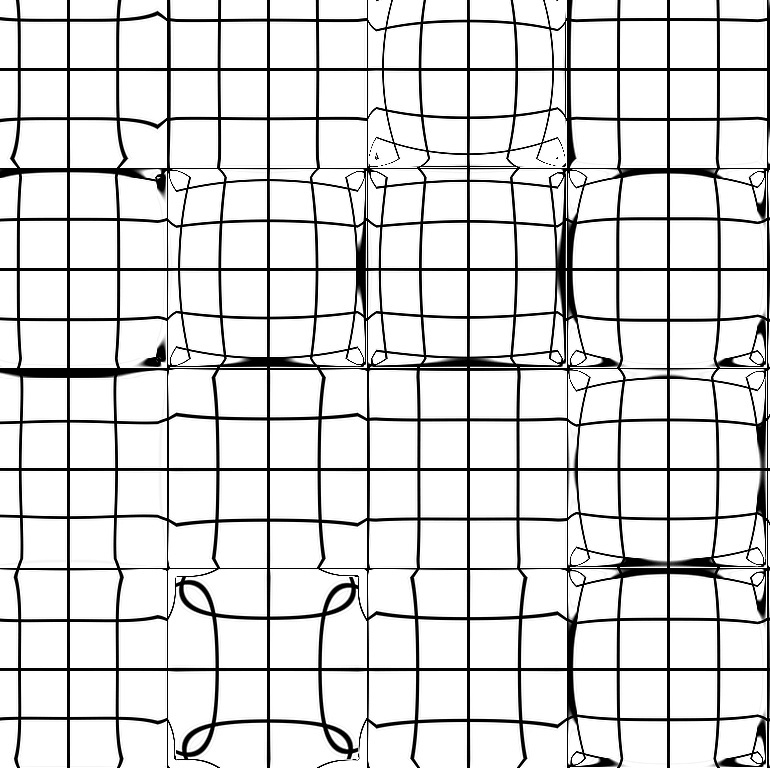
Semantic Image Segmentation facilitates a multitude of real-world applications ranging from autonomous driving over industrial process supervision to vision aids for human beings. These models are usually trained in a supervised fashion using example inputs. Distribution Shifts between these examples and the inputs in operation may cause erroneous segmentations. The robustness of semantic segmentation models against distribution shifts caused by differing camera or lighting setups, lens distortions, adversarial inputs and image corruptions has been topic of recent research. However, robustness against spatially varying radial distortion effects that can be caused by uneven glass structures (e.g. windows) or the chaotic refraction in heated air has not been addressed by the research community yet. We propose a method to synthetically augment existing datasets with spatially varying distortions. Our experiments show, that these distortion effects degrade the performance of state-of-the-art segmentation models. Pretraining and enlarged model capacities proof to be suitable strategies for mitigating performance degradation to some degree, while fine-tuning on distorted images only leads to marginal performance improvements.
翻译:暂无翻译