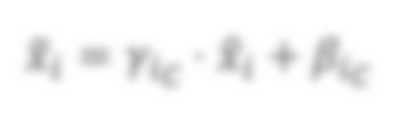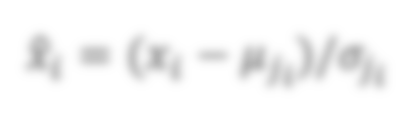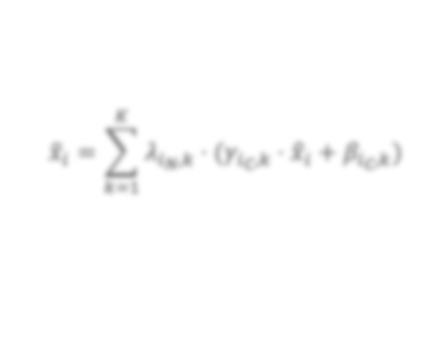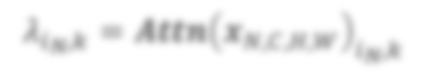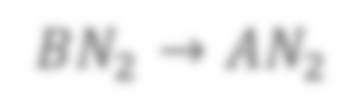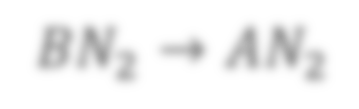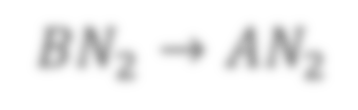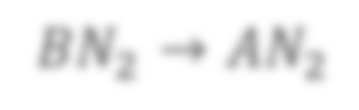In state-of-the-art deep neural networks, both feature normalization and feature attention have become ubiquitous. % with significant performance improvement shown in a vast amount of tasks. They are usually studied as separate modules, however. In this paper, we propose a light-weight integration between the two schema and present Attentive Normalization (AN). Instead of learning a single affine transformation, AN learns a mixture of affine transformations and utilizes their weighted-sum as the final affine transformation applied to re-calibrate features in an instance-specific way. The weights are learned by leveraging channel-wise feature attention. In experiments, we test the proposed AN using four representative neural architectures in the ImageNet-1000 classification benchmark and the MS-COCO 2017 object detection and instance segmentation benchmark. AN obtains consistent performance improvement for different neural architectures in both benchmarks with absolute increase of top-1 accuracy in ImageNet-1000 between 0.5\% and 2.7\%, and absolute increase up to 1.8\% and 2.2\% for bounding box and mask AP in MS-COCO respectively. We observe that the proposed AN provides a strong alternative to the widely used Squeeze-and-Excitation (SE) module. The source codes are publicly available at https://github.com/iVMCL/AOGNet-v2 (the ImageNet Classification Repo) and https://github.com/iVMCL/AttentiveNorm\_Detection (the MS-COCO Detection and Segmentation Repo).
翻译:在最先进的深层神经网络中,特征正常化和特征关注已经变得无处不在。 %, 在大量任务中表现出显著的性能改进。 通常作为单独的模块加以研究。 但是,在本文件中,我们建议在两种模式和目前的加速正常化(AN)之间进行轻量的整合。 AN没有学习单一的松动变异,而是学习了一种结合,并把它们的加权变异作为以实例方式对重新校正特性应用的最后趋同转换。 重量是通过利用频道对特征的注意来学习的。 在实验中,我们用图像Net-1000分类基准和MS-Net的MS- 10000目标检测和实例分解基准中的四种具有代表性的神经结构测试拟议的AN。 AN在两个基准中都取得了持续的性能改进,在图像Net-1-1000中绝对增加最高精度,在0.5 ⁇ /2.7 ⁇ 之间,并且绝对增加至1.8 ⁇ 和2.2°BOV- OS-CO的捆绑框和面具的AS-CO。 我们观察到,拟议的AN-CO 和Ex-L-OG-ODA- reqi- real 提供了一种强大的工具。