
paper: https://arxiv.org/abs/2104.00298
code: https://github.com/google/automl/efficientnetv2
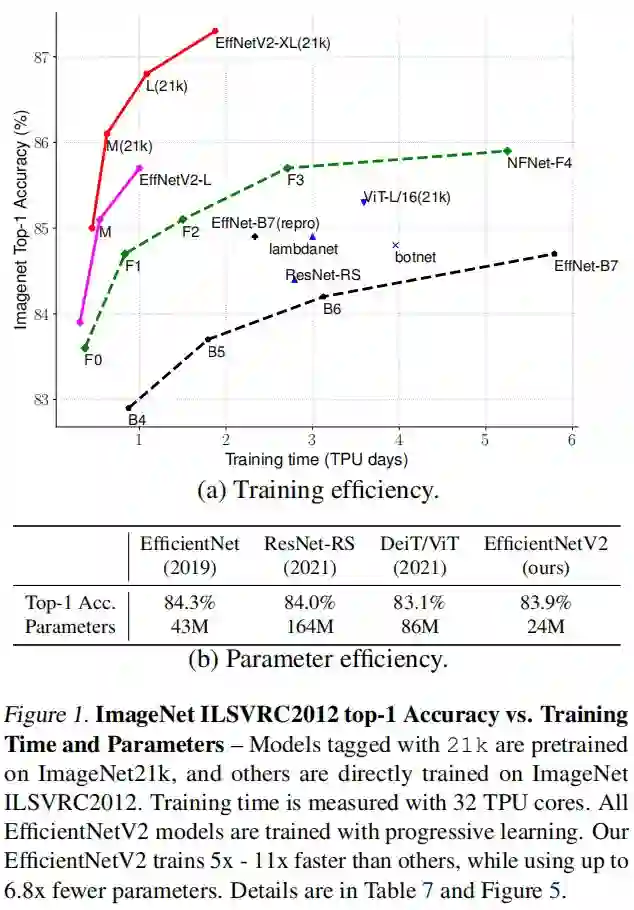
本文是谷歌的MingxingTan与Quov V.Le对EfficientNet的一次升级,旨在保持参数量高效利用的同时尽可能提升训练速度。在EfficientNet的基础上,引入了Fused-MBConv到搜索空间中;同时为渐进式学习引入了自适应正则强度调整机制。两种改进的组合得到了本文的EfficientNetV2,它在多个基准数据集上取得了SOTA性能,且训练速度更快。比如EfficientNetV2取得了87.3%的top1精度且训练速度快5-11倍。
本文提出一种训练速度更快、参数量更少的卷积神经网络EfficientNetV2。我们采用了训练感知NAS与缩放技术对训练速度与参数量进行联合优化,NAS的搜索空间采用了新的op(比如Fused-MBConv)进行扩充。实验表明:相比其他SOTA方案,所提EfficientNetV2收敛速度更快,模型更小(6.8x)。
在训练过程中,我们可以通过逐步提升图像大小得到加速,但通常会造成性能掉点。为补偿该性能损失,我们提出了一种改进版的渐进学习方式,它自适应的根据图像大小调整正则化因子,比如dropout、数据增广。
受益于渐进学习方式,所提EfficientNetV2在CIFAR/Cars/Flowers数据集上显著优于其他模型;通过在ImageNet21K数据集上预训练,所提模型在ImageNet上达到了87.3%的top1精度,以2.0%精度优于ViT,且训练速度更快(5x-11x)。
成为VIP会员查看完整内容
相关内容
专知会员服务
27+阅读 · 2019年11月24日
Arxiv
4+阅读 · 2021年5月27日
Arxiv
3+阅读 · 2021年5月12日
相关主题
相关VIP内容
专知会员服务
27+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
4+阅读 · 2021年5月27日
Arxiv
3+阅读 · 2021年5月12日