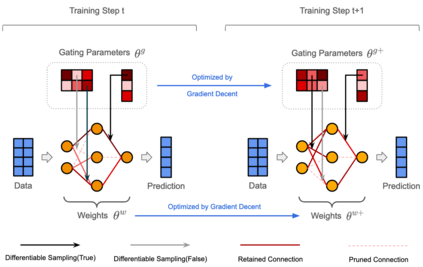
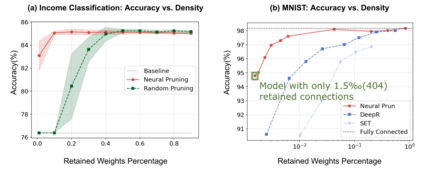
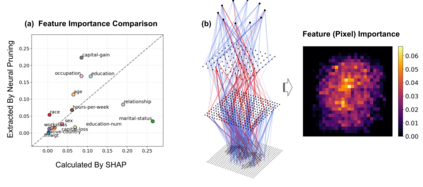
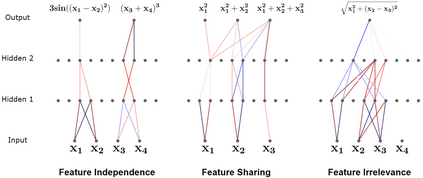
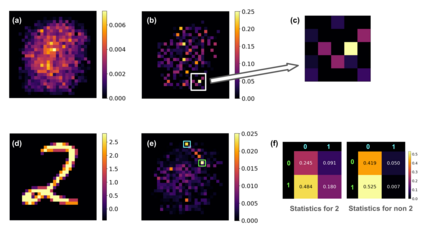
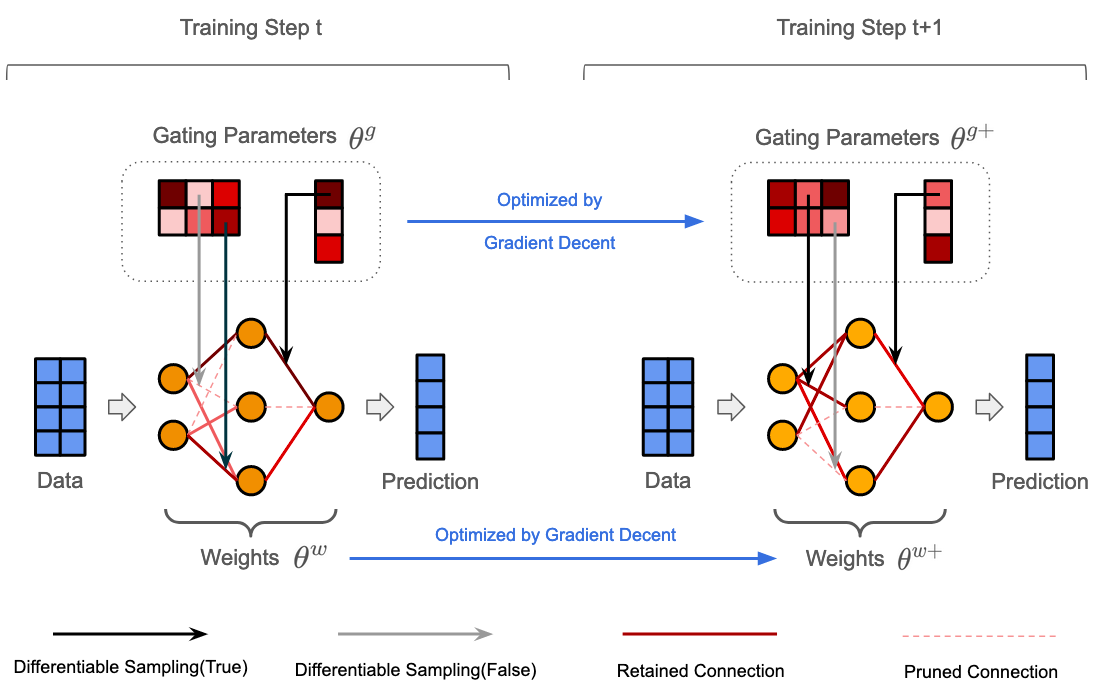
The rapid increase in the parameters of deep learning models has led to significant costs, challenging computational efficiency and model interpretability. In this paper, we introduce a novel and straightforward neural network pruning framework that incorporates the Gumbel-Softmax technique. This framework enables the simultaneous optimization of a network's weights and topology in an end-to-end process using stochastic gradient descent. Empirical results demonstrate its exceptional compression capability, maintaining high accuracy on the MNIST dataset with only 0.15\% of the original network parameters. Moreover, our framework enhances neural network interpretability, not only by allowing easy extraction of feature importance directly from the pruned network but also by enabling visualization of feature symmetry and the pathways of information propagation from features to outcomes. Although the pruning strategy is learned through deep learning, it is surprisingly intuitive and understandable, focusing on selecting key representative features and exploiting data patterns to achieve extreme sparse pruning. We believe our method opens a promising new avenue for deep learning pruning and the creation of interpretable machine learning systems.
翻译:暂无翻译