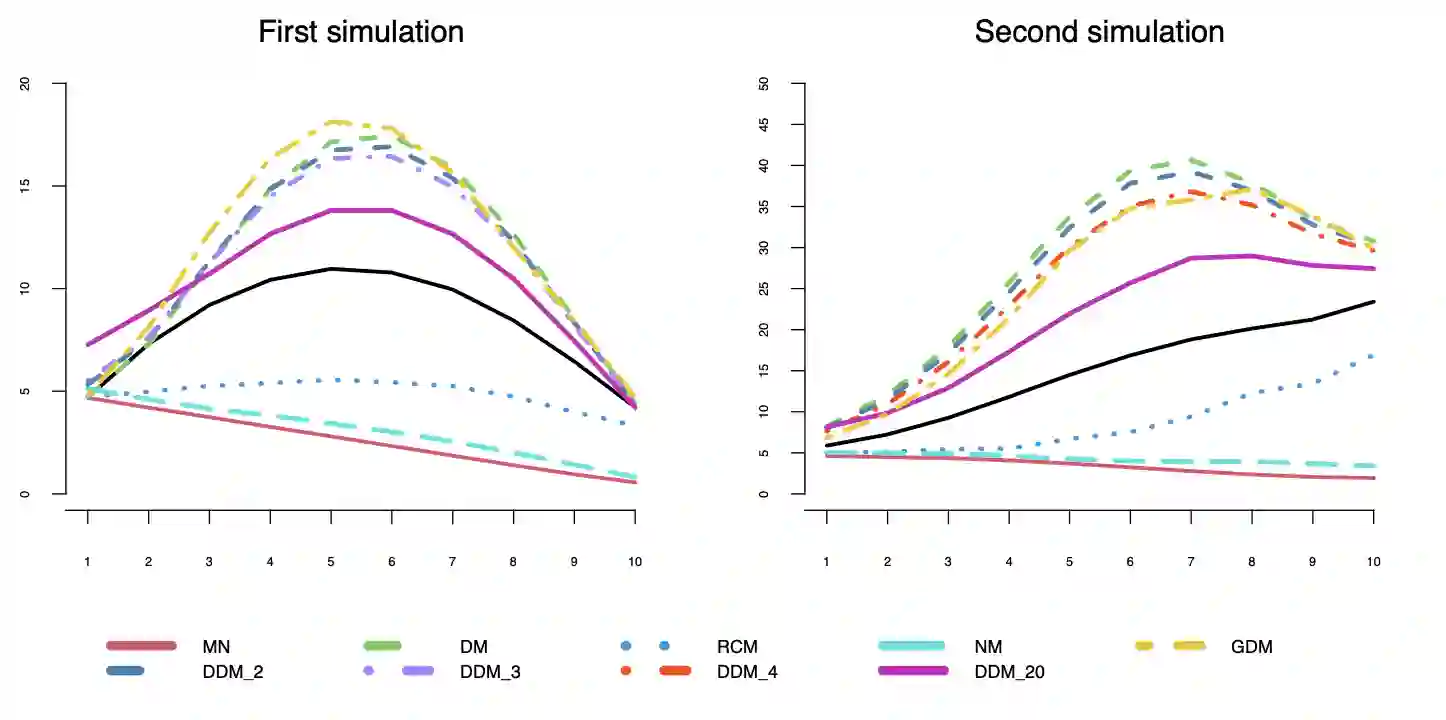
The problem of overdispersion in multivariate count data is a challenging issue. Nowadays, it covers a central role mainly due to the relevance of modern technologies data, such as Next Generation Sequencing and textual data from the web or digital collections. This work presents a comprehensive analysis of the likelihood-based models for extra-variation data proposed in the scientific literature. Particular attention will be paid to the models feasible for high-dimensional data. A new approach together with its parametric-estimation procedure is proposed. It is a deeper version of the Dirichlet-Multinomial distribution and it leads to important results allowing to get a better approximation of the observed variability. A significative comparison of these models is made through two different simulation studies that both confirm that the new model considered in this work allows to achieve the best results.
翻译:多变量计数数据过于分散的问题是一个具有挑战性的问题。如今,它涵盖了主要由于现代技术数据的相关性而起的中心作用,例如下一代测序和来自网络或数字收集的文字数据。这项工作对科学文献中提议的基于可能性的外变量数据模型进行了全面分析。将特别注意对高维数据可行的模型。提出了一种新的方法及其参数估计程序。它是Drichlet-Multinomial分布的更深层次版本,并导致重要的结果,使得观测到的变异性得到更好的近似。通过两个不同的模拟研究对这些模型进行了象征性的比较,这两个研究都证实这项工作中考虑的新模型能够取得最佳结果。