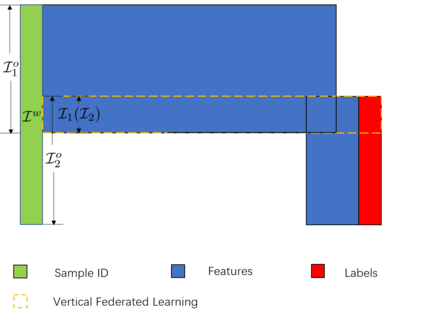
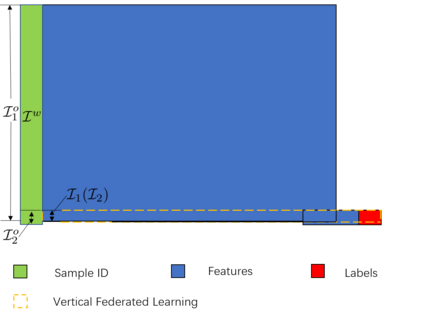
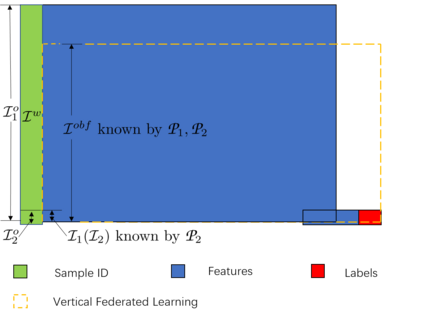
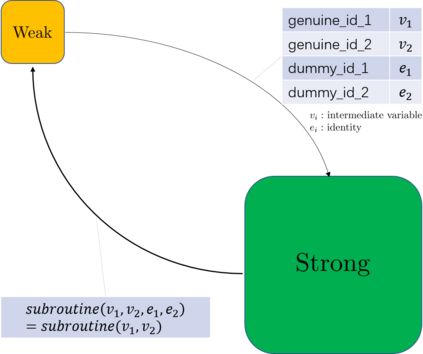
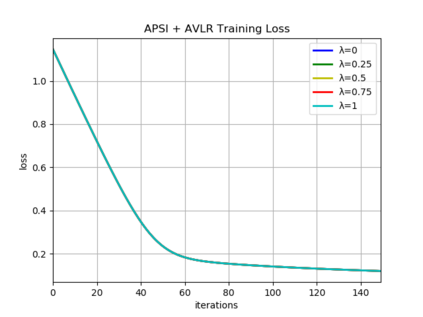
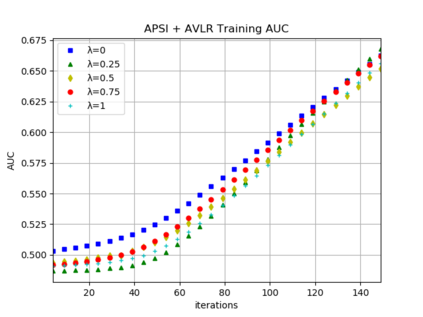
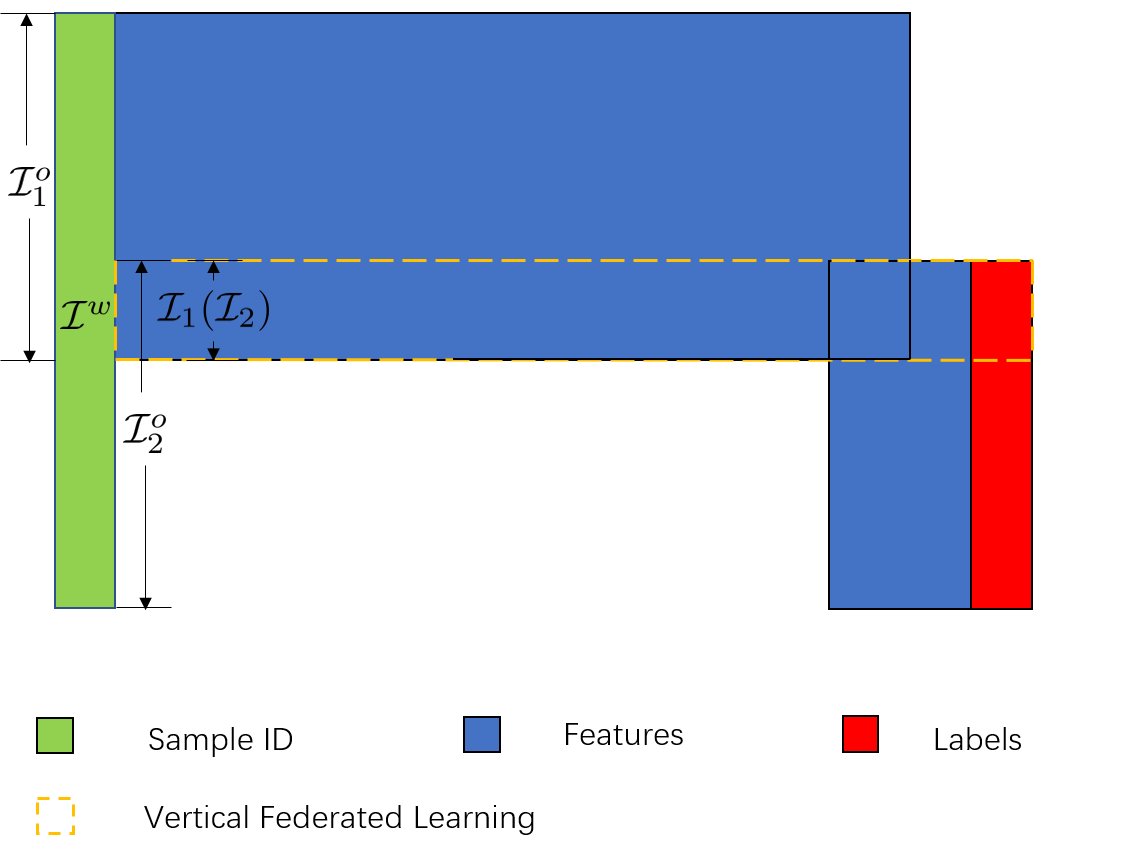
Federated learning is a distributed machine learning method that aims to preserve the privacy of sample features and labels. In a federated learning system, ID-based sample alignment approaches are usually applied with few efforts made on the protection of ID privacy. In real-life applications, however, the confidentiality of sample IDs, which are the strongest row identifiers, is also drawing much attention from many participants. To relax their privacy concerns about ID privacy, this paper formally proposes the notion of asymmetrical vertical federated learning and illustrates the way to protect sample IDs. The standard private set intersection protocol is adapted to achieve the asymmetrical ID alignment phase in an asymmetrical vertical federated learning system. Correspondingly, a Pohlig-Hellman realization of the adapted protocol is provided. This paper also presents a genuine with dummy approach to achieving asymmetrical federated model training. To illustrate its application, a federated logistic regression algorithm is provided as an example. Experiments are also made for validating the feasibility of this approach.
翻译:联邦学习是一种分散的机器学习方法,目的是保护样本特征和标签的隐私。在一个联合学习系统中,通常在很少努力保护身份隐私权的情况下采用基于身份的样本校准方法。但是,在实际应用中,作为最强的行标识的样本身份的保密性也引起许多参与者的极大关注。为了放松他们对身份隐私的隐私关切,本文件正式提出了对称垂直联合学习的概念,并说明了保护样本身份的方法。标准私密套交叉协议经过调整,以在对称的垂直联合学习系统中实现对称身份识别调整阶段。相应提供了经过调整的协议的Pohlig-Hellman实现情况。本文还提出了实现对称联邦模式培训的真实和虚伪的方法。为了说明其应用,提供了一种联合后勤回归算法作为实例。还进行了实验,以验证这一方法的可行性。