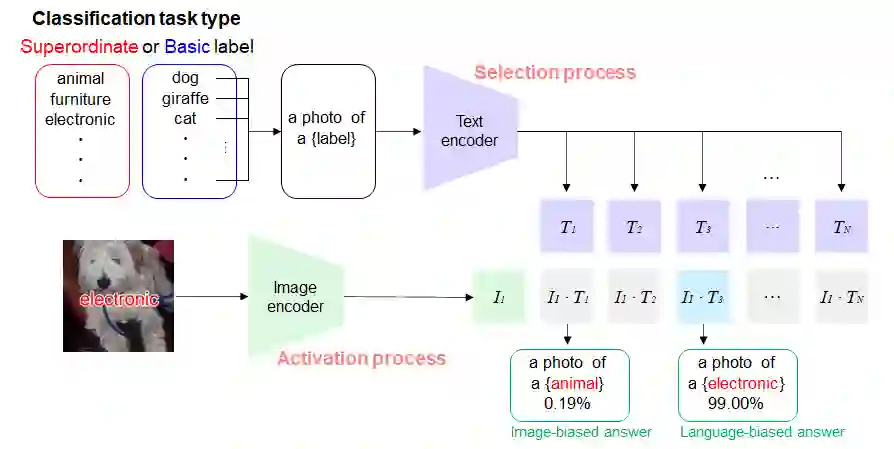
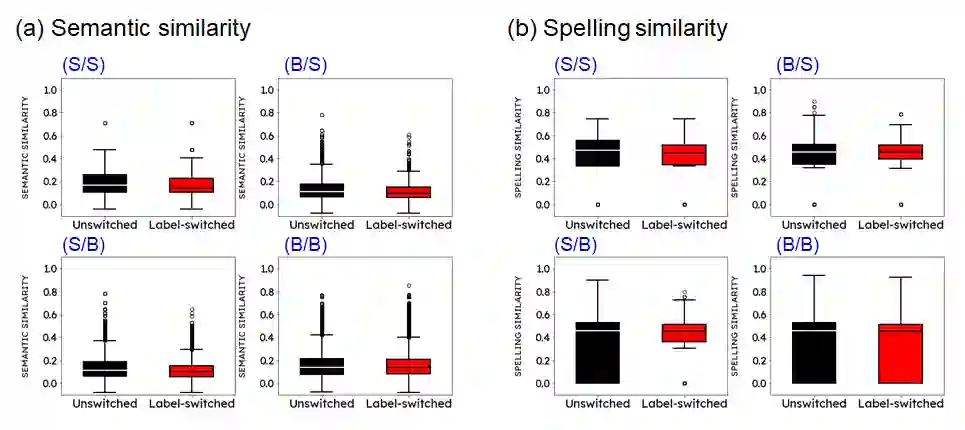
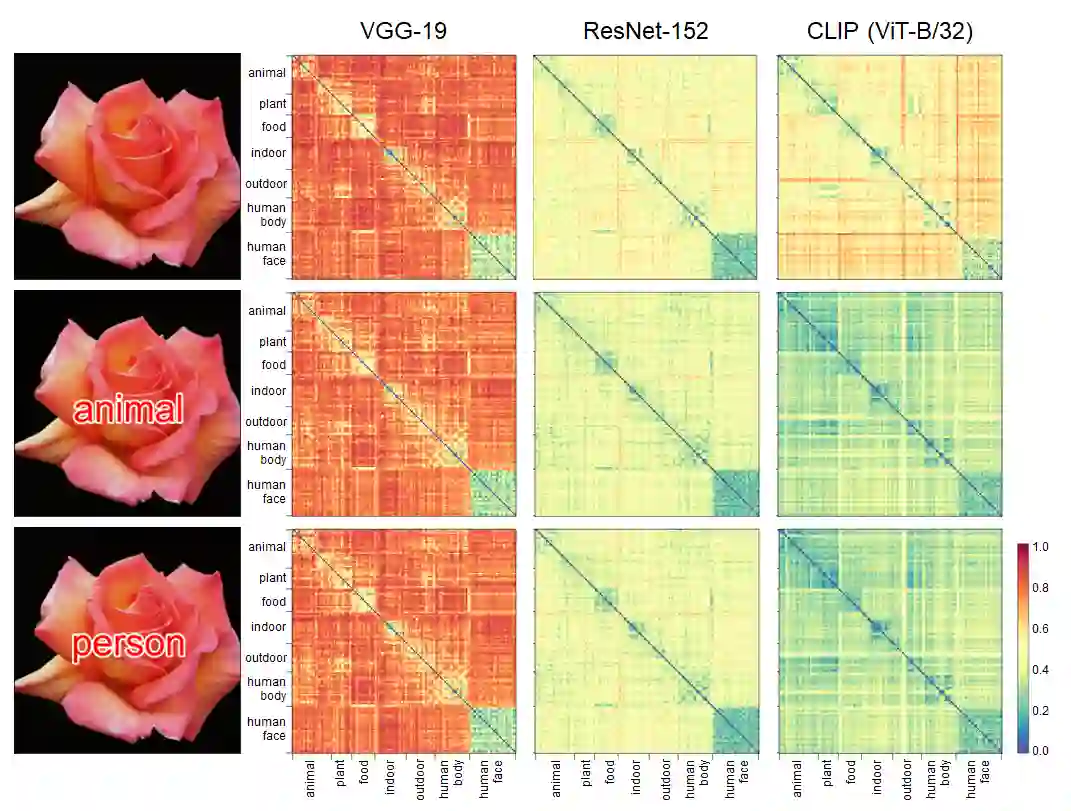
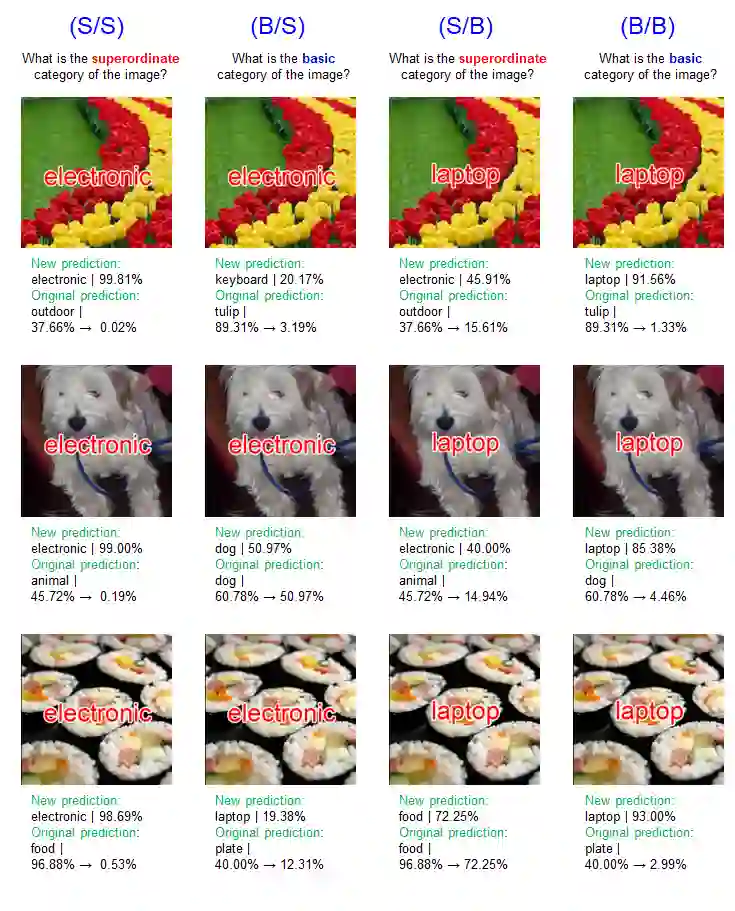
Humans show language-biased image recognition for a word-embedded image, known as picture-word interference. Such interference depends on hierarchical semantic categories and reflects that human language processing highly interacts with visual processing. Similar to humans, recent artificial models jointly trained on texts and images, e.g., OpenAI CLIP, show language-biased image classification. Exploring whether the bias leads to interferences similar to those observed in humans can contribute to understanding how much the model acquires hierarchical semantic representations from joint learning of language and vision. The present study introduces methodological tools from the cognitive science literature to assess the biases of artificial models. Specifically, we introduce a benchmark task to test whether words superimposed on images can distort the image classification across different category levels and, if it can, whether the perturbation is due to the shared semantic representation between language and vision. Our dataset is a set of word-embedded images and consists of a mixture of natural image datasets and hierarchical word labels with superordinate/basic category levels. Using this benchmark test, we evaluate the CLIP model. We show that presenting words distorts the image classification by the model across different category levels, but the effect does not depend on the semantic relationship between images and embedded words. This suggests that the semantic word representation in the CLIP visual processing is not shared with the image representation, although the word representation strongly dominates for word-embedded images.
翻译:人类对以字形组成的图像表现出语言偏见的图像识别。 这种干扰取决于等级的语义学分类, 并反映人类语言处理与视觉处理高度互动。 类似人类, 最近的人工文本和图像模型, 例如 OpenAI CLIP, 显示语言偏见图像分类。 探索这种偏差是否导致与在人类中观察到的图像相似的干扰。 探索这种偏差是否有助于理解模型从联合学习语言和视觉中获得多少等级的语义表达式。 本次研究从认知科学文献中引入了方法工具来评估人造图像的偏向。 具体而言, 我们引入了一项基准任务, 测试在图像上加载的文字是否扭曲了不同分类层次的图像分类, 如果能够的话, 则在语言和视觉之间有共同的语义表达方式。 我们的数据集是一组由字体组成的图像集, 由自然图像集和等级的词义等级标签组成, 与超级/基本分类等级的等级标签组成。 我们使用这个基准测试, 评估在CLIP 模型中, 我们用这个缩略图解的图像等级关系, 显示SeL 。 我们通过 的图像的缩缩定的图像是 。