
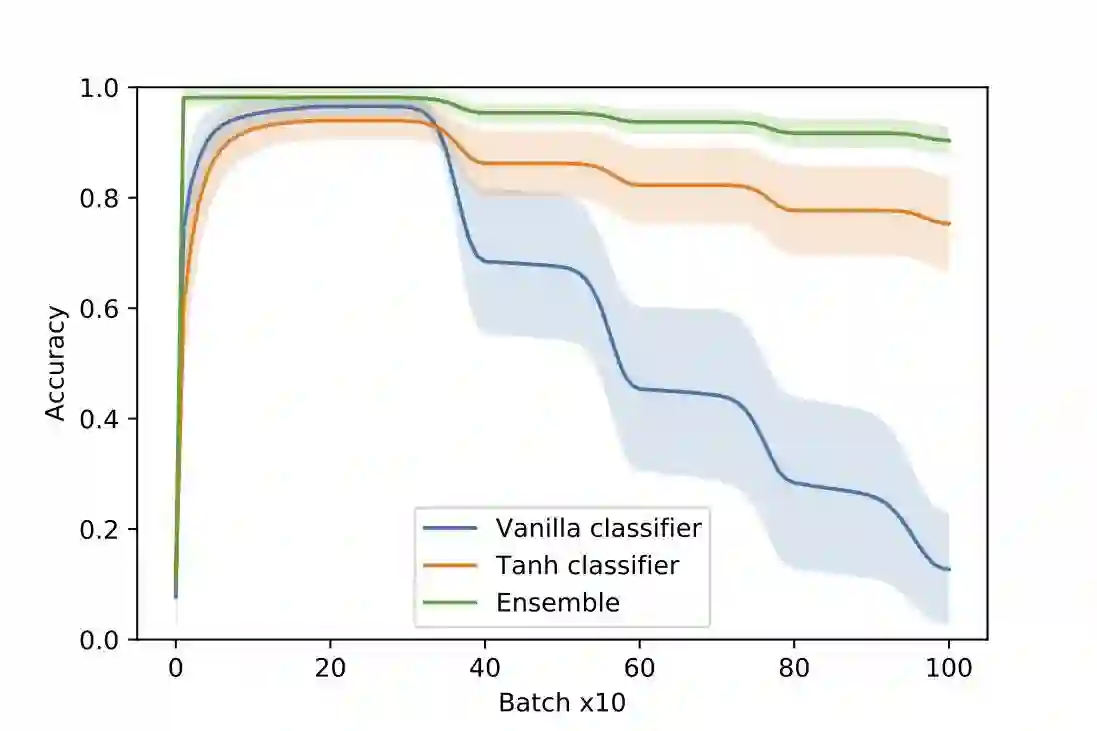
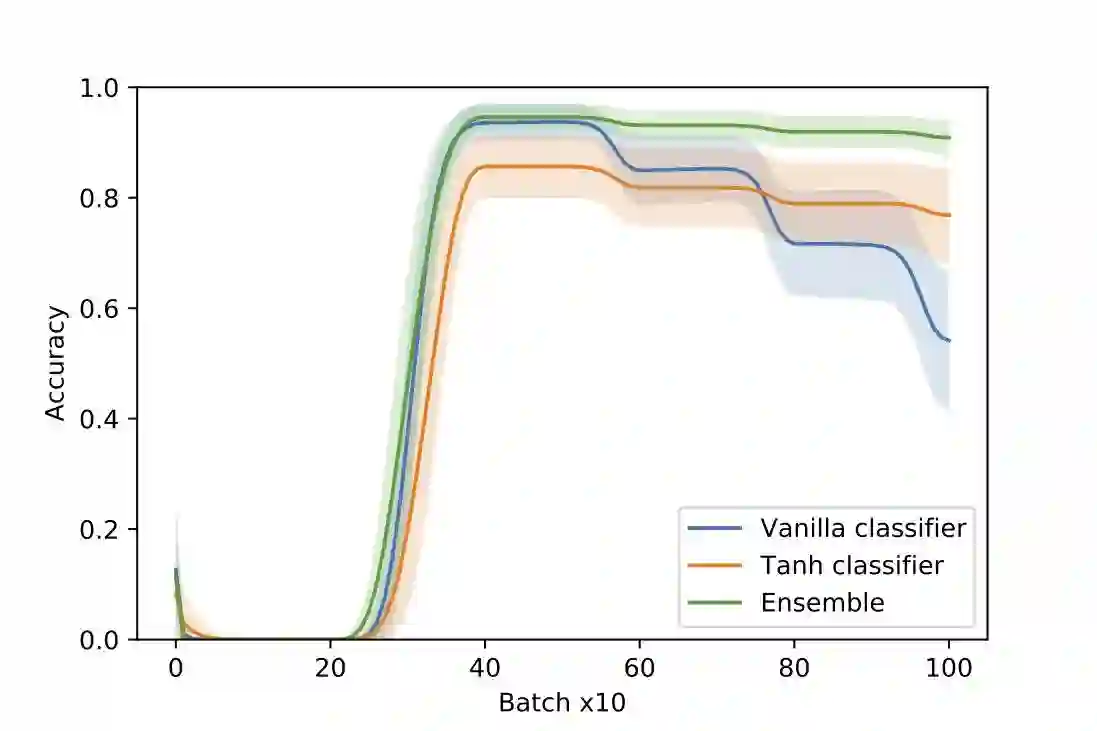
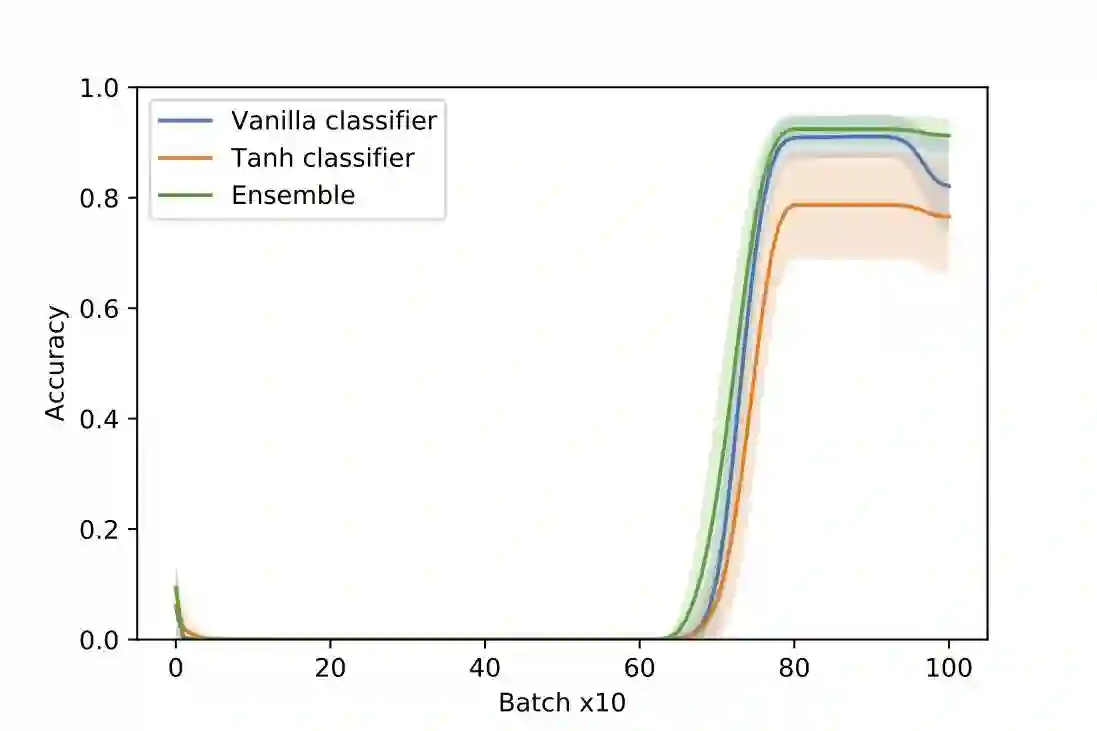
We present an architecture that is effective for continual learning in an especially demanding setting, where task boundaries do not exist or are unknown. Our architecture comprises an encoder, pre-trained on a separate dataset, and an ensemble of simple one-layer classifiers. Two main innovations are required to make this combination work. First, the provision of suitably generic pre-trained encoders has been made possible thanks to recent progress in self-supervised training methods. Second, pairing each classifier in the ensemble with a key, where the key-space is identical to the latent space of the encoder, allows them to be used collectively, yet selectively, via k-nearest neighbour lookup. We show that models trained with the encoders-and-ensembles architecture are state-of-the-art for the task-free setting on standard image classification continual learning benchmarks, and improve on prior state-of-the-art by a large margin in the most challenging cases. We also show that the architecture learns well in a fully incremental setting, where one class is learned at a time, and we demonstrate its effectiveness in this setting with up to 100 classes. Finally, we show that the architecture works in a task-free continual learning context where the data distribution changes gradually, and existing approaches requiring knowledge of task boundaries cannot be applied.
翻译:我们展示了一个在特别困难的环境中持续学习的有效架构,在这种环境中任务界限不存在或未知。我们的架构包括一个编码器,在单独的数据集上预先培训,以及一组简单的单层分类器。需要两项主要创新才能使这种组合发挥作用。首先,由于在自我监督的培训方法方面最近取得的进展,提供了适当的通用的、经过培训的预科解码器。第二,将每个分类器与钥匙配对在一起,关键空间与编码器的潜在空间相同,允许它们被集体、但有选择地使用,通过K最接近的邻居的外观来加以使用。我们显示,经过对编码器和组合结构进行训练的模式是使这种组合发挥作用的最先进的。首先,由于在自我监督的培训方法方面最近取得的进展,提供了适当的通用的、经过预先培训的编码解密的编码器。第二,将每个分类器与钥匙配对在一起,使每个分类器与钥匙空间与编码器的潜在空间完全相同,从而允许它们被集体、但又有选择地使用。我们显示,通过 k- 最接近的邻居的外观的外观来加以使用。我们展示的是,在100个层次上进行自由分配时,我们无法持续地展示它的有效性,在这种结构中学习的任务中,在100个阶段里学习任务中,我们无法显示其持续地展示它是如何在100个层次上学习的任务。


相关内容

Source: Apple - iOS 8

