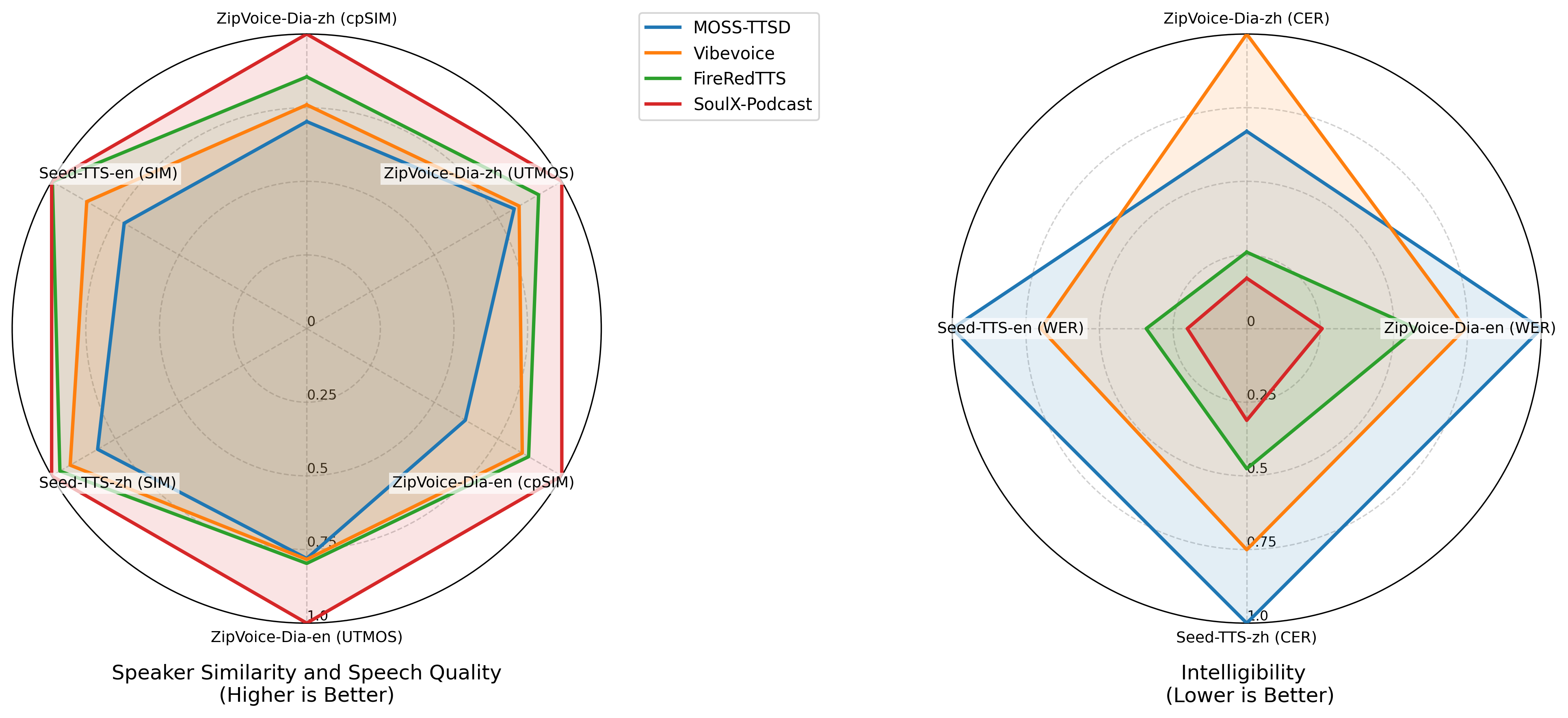
Recent advances in text-to-speech (TTS) synthesis have significantly improved speech expressiveness and naturalness. However, most existing systems are tailored for single-speaker synthesis and fall short in generating coherent multi-speaker conversational speech. This technical report presents SoulX-Podcast, a system designed for podcast-style multi-turn, multi-speaker dialogic speech generation, while also achieving state-of-the-art performance in conventional TTS tasks. To meet the higher naturalness demands of multi-turn spoken dialogue, SoulX-Podcast integrates a range of paralinguistic controls and supports both Mandarin and English, as well as several Chinese dialects, including Sichuanese, Henanese, and Cantonese, enabling more personalized podcast-style speech generation. Experimental results demonstrate that SoulX-Podcast can continuously produce over 90 minutes of conversation with stable speaker timbre and smooth speaker transitions. Moreover, speakers exhibit contextually adaptive prosody, reflecting natural rhythm and intonation changes as dialogues progress. Across multiple evaluation metrics, SoulX-Podcast achieves state-of-the-art performance in both monologue TTS and multi-turn conversational speech synthesis.
翻译:暂无翻译