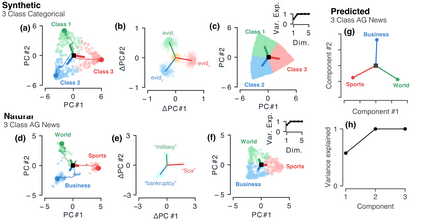
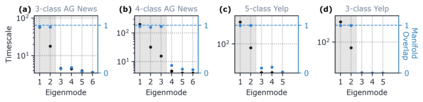
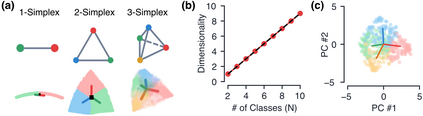
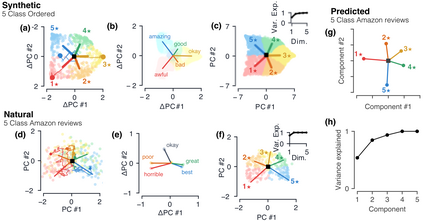
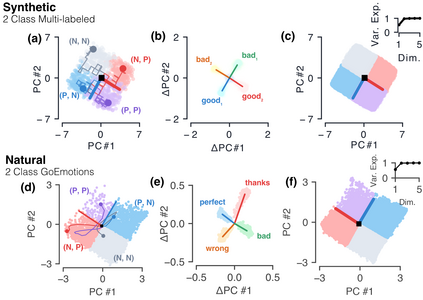
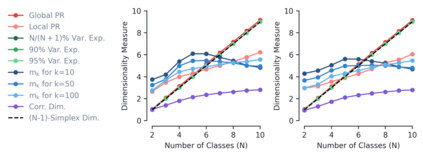
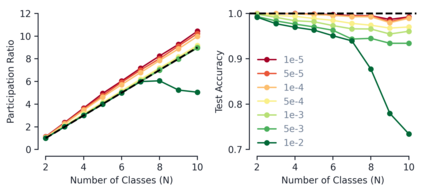
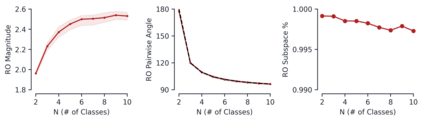
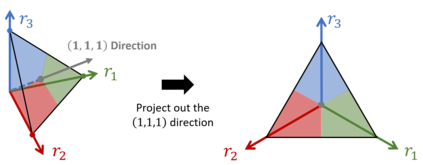
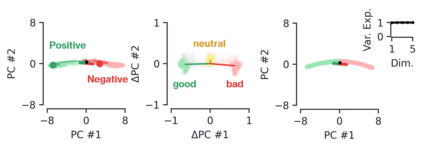
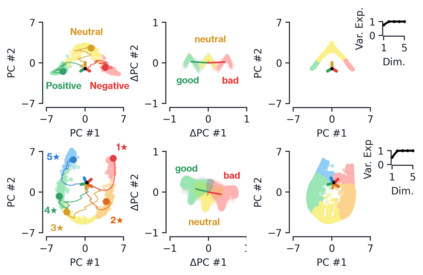
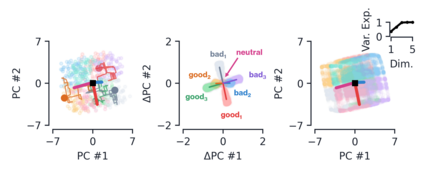
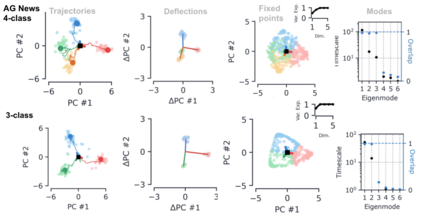
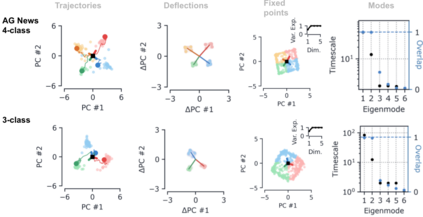
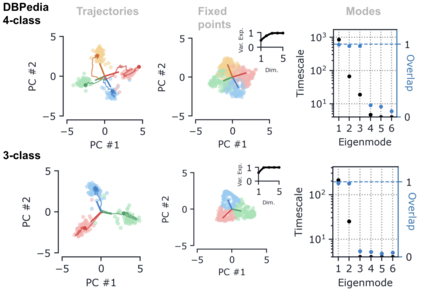
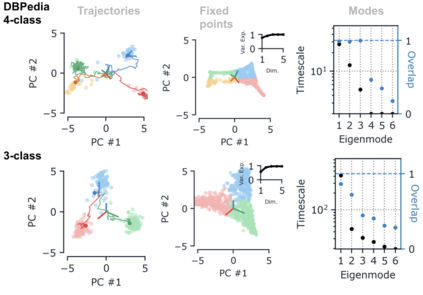
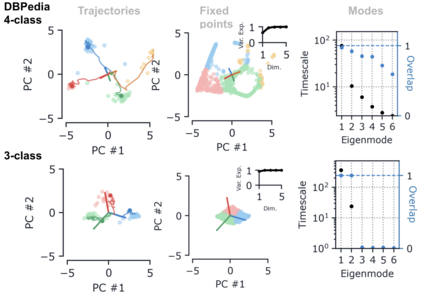
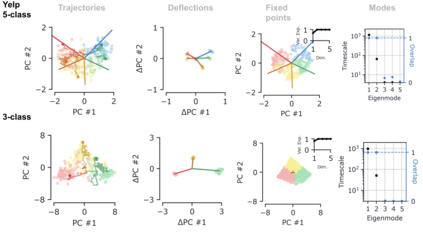
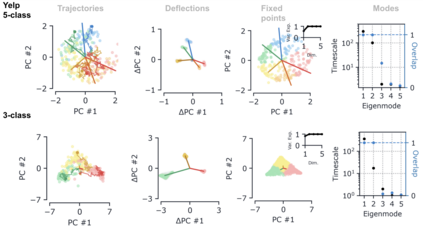
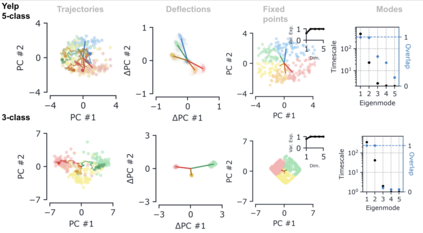
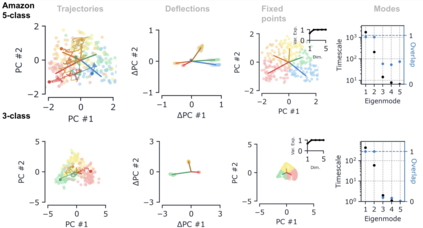
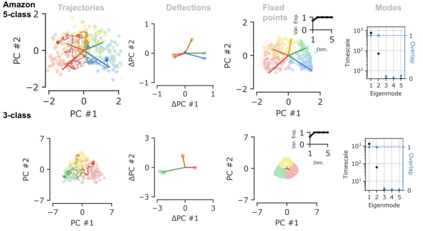
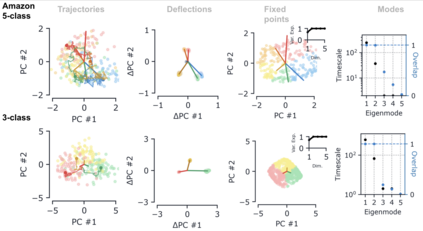
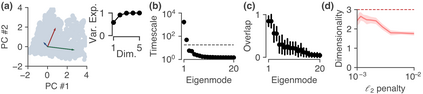
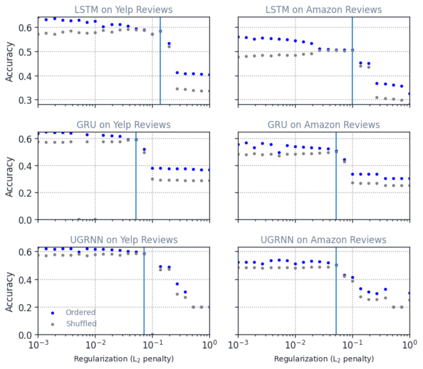
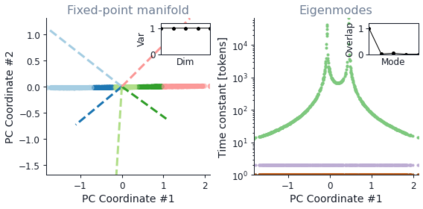
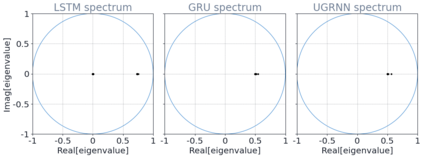
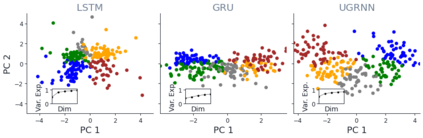
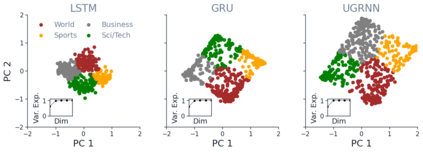
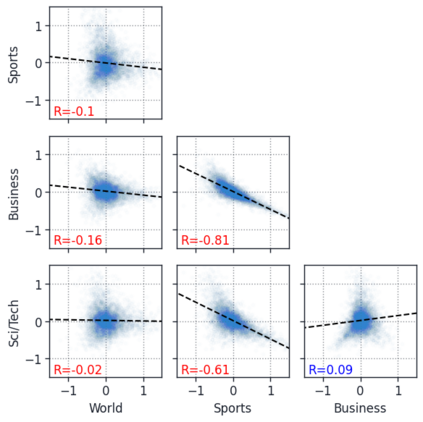
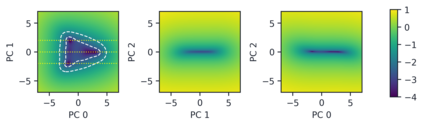
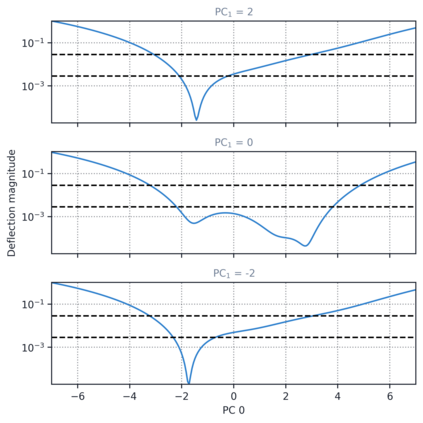
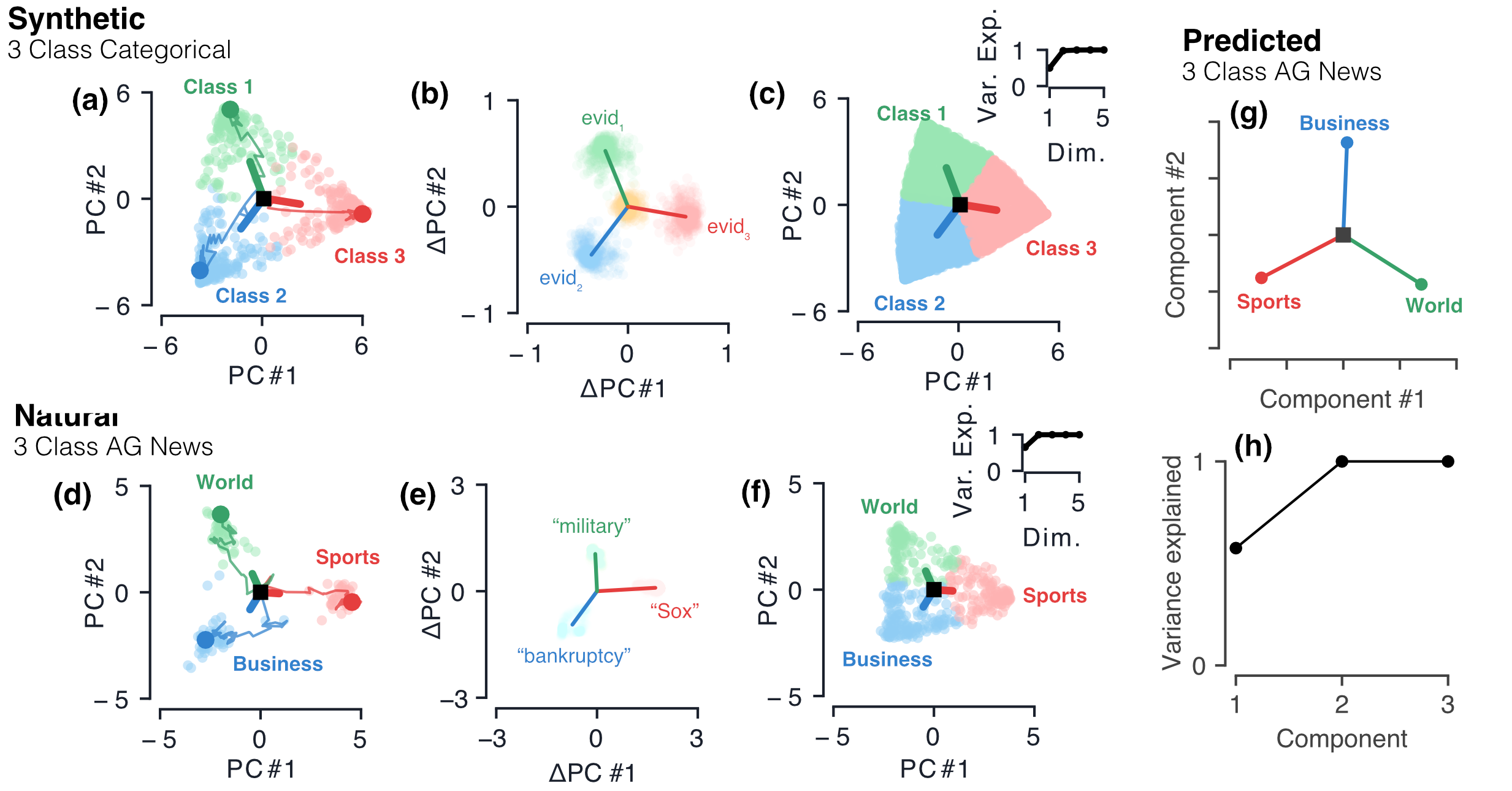
Despite the widespread application of recurrent neural networks (RNNs) across a variety of tasks, a unified understanding of how RNNs solve these tasks remains elusive. In particular, it is unclear what dynamical patterns arise in trained RNNs, and how those patterns depend on the training dataset or task. This work addresses these questions in the context of a specific natural language processing task: text classification. Using tools from dynamical systems analysis, we study recurrent networks trained on a battery of both natural and synthetic text classification tasks. We find the dynamics of these trained RNNs to be both interpretable and low-dimensional. Specifically, across architectures and datasets, RNNs accumulate evidence for each class as they process the text, using a low-dimensional attractor manifold as the underlying mechanism. Moreover, the dimensionality and geometry of the attractor manifold are determined by the structure of the training dataset; in particular, we describe how simple word-count statistics computed on the training dataset can be used to predict these properties. Our observations span multiple architectures and datasets, reflecting a common mechanism RNNs employ to perform text classification. To the degree that integration of evidence towards a decision is a common computational primitive, this work lays the foundation for using dynamical systems techniques to study the inner workings of RNNs.
翻译:尽管在各种任务中广泛应用了经常性神经网络(RNN),但对于RNN如何解决这些任务的统一理解仍然难以实现。特别是,不清楚在经过培训的RNN中会产生哪些动态模式,以及这些模式如何取决于培训数据集或任务。这项工作在特定自然语言处理任务的背景下解决了这些问题:文本分类。我们利用动态系统分析工具,研究在自然和合成文本分类任务电池方面受过训练的经常性网络。我们发现这些经过培训的RNN的动态既可解释,又低度。我们发现这些经过培训的RNN的动态是可解释的。具体地说,在建筑和数据集之间,RNNN在处理文本时为每个类别积累证据,使用低维的吸引器作为基本机制。此外,吸引器的维度和几何度是由培训数据集的结构决定的;特别是,我们用动态系统计算的简单字数统计数据来预测这些属性。我们的观测涉及多个结构和数据集,反映了用于进行文本分类的通用机制。具体地说,RNNNN采用低维吸引器的多种机制进行文本分类。此外,将模型用于进行基础的模型的计算。