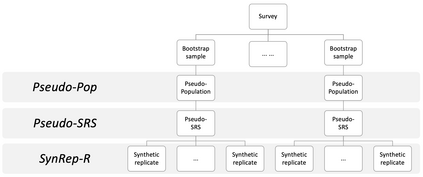
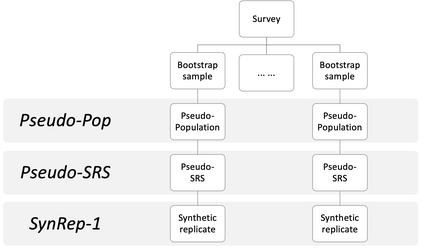
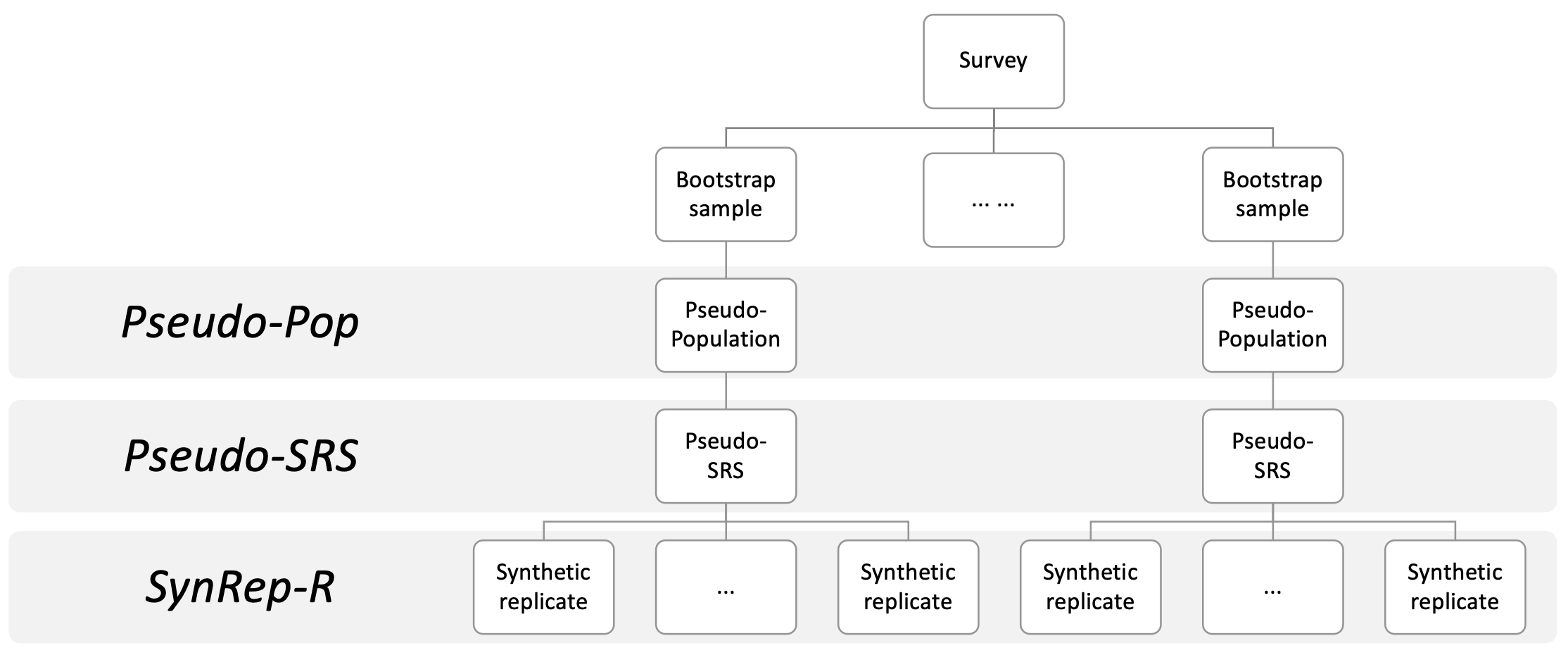
When seeking to release public use files for confidential data, statistical agencies can generate fully synthetic data. We propose an approach for making fully synthetic data from surveys collected with complex sampling designs. Specifically, we generate pseudo-populations by applying the weighted finite population Bayesian bootstrap to account for survey weights, take simple random samples from those pseudo-populations, estimate synthesis models using these simple random samples, and release simulated data drawn from the models as the public use files. We use the framework of multiple imputation to enable variance estimation using two data generation strategies. In the first, we generate multiple data sets from each simple random sample, whereas in the second, we generate a single synthetic data set from each simple random sample. We present multiple imputation combining rules for each setting. We illustrate each approach and the repeated sampling properties of the combining rules using simulation studies.
翻译:暂无翻译