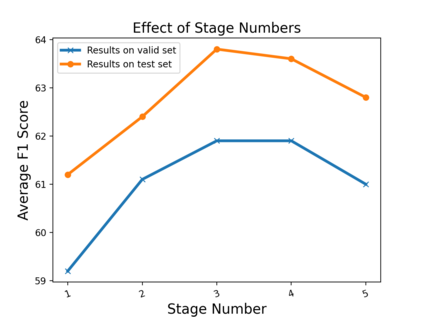
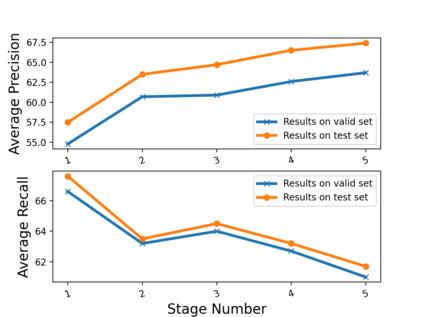
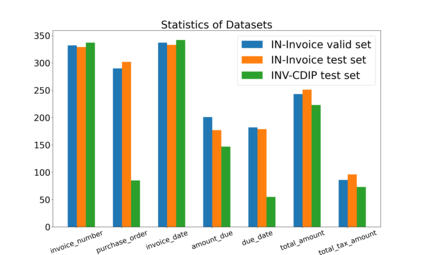
We propose a novel framework to conduct field extraction from forms with unlabeled data. To bootstrap the training process, we develop a rule-based method for mining noisy pseudo-labels from unlabeled forms. Using the supervisory signal from the pseudo-labels, we extract a discriminative token representation from a transformer-based model by modeling the interaction between text in the form. To prevent the model from overfitting to label noise, we introduce a refinement module based on a progressive pseudo-label ensemble. Experimental results demonstrate the effectiveness of our framework.
翻译:我们提出一个新的框架,用未贴标签的数据从表格中进行实地抽取。为了给培训过程设套套,我们制定了一种基于规则的方法,从未贴标签的表格中挖掘噪音的假标签。我们利用假标签的监督信号,通过模拟表格中文本之间的相互作用,从基于变压器的模型中提取一种歧视性的象征性表述。为了防止模型过度适应标签噪音,我们引入了一个基于进步的伪标签合奏的完善模块。实验结果证明了我们框架的有效性。