【论文】Awesome Relation Extraction Paper(关系抽取)(PART III)
作者:高开远
学校:上海交通大学
研究方向:自然语言处理
0. 写在前面
回头看了一遍之前的博客,好些介绍的论文主要是属于关系分类的领域,于是就把前几篇的标题给修改了一下哈哈。关系分类和之前的文本分类,基于目标词的情感识别还都挺像的,baseline模型也都差不多。首先对之前的关系分类算法做个总结,然后进入今天的关系抽取(relation extraction)部分。
关系分类总结
输入层标配:word embedding + position embedding
特征提取层可以选取:CNN/RNN/LSTM/Attention等,效果最好的是加上attention层的模型叠加
损失函数:实验证明针对该任务margin-based ranking loss比传统多分类softmax + cross entropy表现要好
可以改进的方向:单纯从神经网络的结构出发,改进的余地很小了,因为这个数据集很封闭, 可以利用的信息仅仅是这些sentence 以及 标注的word entity。在上述的基础上可能可以考虑的方向,从两个target word与relation的关系上加约束。
1. A glance at Distant Supervision(DS)
因为后面的文章中会设计远程监督的内容,所以就单独拎出来说明一下。
远程监督提出来的初衷是为了解决标注数据量太小的问题,以SemEval 2010 Task 8数据集为例,训练数据8000条,测试数据2717条,对于深度学习网络来说确实有点小。那么远程监督是怎么来做这个增加数据量的工作的呢?第一个将远程监督运用到关系抽取任务中的是Distant supervision for relation extraction without labeled data
If two entities have a relationship in a known knowledge base, then all sentences that mention these two entities will express that relationship in some way.
基本假设: 如果两个实体在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
具体步骤:(1)从知识库中抽取存在关系的实体对;(2)从非结构化文本中抽取含有实体对的句子作为训练样例,然后提取特征训练分类器。
存在问题:假设太强会引入噪音数据,包含两个实体的句子不一定和数据库中的关系一致,如下,右侧非结构化文本中第一句成立,但是第二句不成立。

改进方法: 提出多示例学习(Multi Instance Learning)的方法
多示例学习可以被描述为:假设训练数据集中的每个数据是一个包(Bag),每个包都是一个示例(instance)的集合,每个包都有一个训练标记,而包中的示例是没有标记的;如果包中至少存在一个正标记的示例,则包被赋予正标记;而对于一个有负标记的包,其中所有的示例均为负标记。(这里说包中的示例没有标记,而后面又说包中至少存在一个正标记的示例时包为正标记包,是相对训练而言的,也就是说训练的时候是没有给示例标记的,只是给了包的标记,但是示例的标记是确实存在的,存在正负示例来判断正负类别)。通过定义可以看出,与监督学习相比,多示例学习数据集中的样本示例的标记是未知的,而监督学习的训练样本集中,每个示例都有一个一已知的标记;与非监督学习相比,多示例学习仅仅只有包的标记是已知的,而非监督学习样本所有示例均没有标记。但是多示例学习有个特点就是它广泛存在真实的世界中,潜在的应用前景非常大。from http://blog.csdn.net/tkingreturn/article/details/39959931
利用远程监督技术生成关系抽取训练实例的噪音数据如何过滤?
2. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks(Zeng/ EMNLP2015)
可以说是作者自己之前的那篇文章的改进版,提出了两点现存的缺陷以及相对应的改进方式:
远程监督标注数据的噪音很大,使用多示例学习的方式;
原始方法大都是基于词法、句法特征来处理, 无法自动提取特征。而且句法树等特征在句子长度边长的话,正确率很显著下降。提出改进的Piecewise Convolutional Neural Networks (PCNNs)
论文提出的整体模型框架如下, 主要包括四个部分:
Vector Representation,
Convolution,
Piecewise Max Pooling
Softmax Output
网络的设计就是很简单的embedding+cnn+pooling。需要提一下的是这里对pooling层进行了改进,不再使用整个channel的唯一max,而是对卷积后得到的输出划分成三块,分别是两个实体部分和一个不包含实体的部分,这样对这三块做piecewise max pooling,得到三个向量。最终将三个卷积核的输出做一样的操作拼接起来后做softmax分类,最终得到输出向量o。

Multi-instance Learning
首先给出几个定义:
bag:数据中包含两个entity的所有句子称为一个bag
:表示训练数据中的T个bags,每个bag都有一个relation标签
:表示第i个bag中有 qi个instance,也就是句子,假设每个instance是独立的
o 便是给定 m_{i}^{j} 的网络模型的输出(未经过softmax),其中 or 表示第r个relation的score
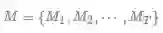
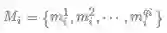
这样,经过softmax就可以计算每一个类别的概率:
模型的目的是得到每个bag的标签,所以损失函数是基于bag定义的,这里采用了“at-least-once assumption”,即假设每个bag内都肯至少有一个标注正确的句子,那么就找出bag中得分最高的句子来求损失函数: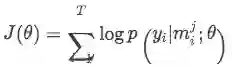
算法步骤总结如下:
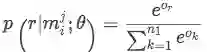
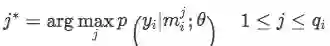

3. Neural Relation Extraction with Selective Attention over Instances(Lin/ACL2016)
在上一节的CNN基础上引入句子级别的Attention机制。也是针对远程监督过程会引入错误标签的问题,指出在Zeng 2015年的CNN模型中只考虑了每一个bag中置信度最高的instance,这样做会忽略bag中的其他句子丢失很多的信息。因此提出对一个bag中的所有句子经过CNN处理后再进行Attention操作分配权重,可以充分利用样本信息。模型整体框架如下:

其中最底层的输入 xi 是某一个bag中的句子,接着对每一个句子都做同样的CNN操作(这一部分与前一节PCNN相同),最终得到每个句子的表示 ri 。然后为了更好地利用bag内的句子信息,对所有的instance衡量对该bag对应的标签的权重:
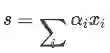 其中alpha为权重系数,文中给出两种计算方式:
其中alpha为权重系数,文中给出两种计算方式:
Average:
,直接做平均,错误样本的噪声很大;
Selective Attention: 就是一般的key-query-value的attention计算。
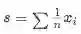
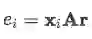
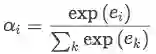
其中 ei 表示attention score,用于计算某个句子与该bag对应的relation之间的匹配程度。
在经过attention就得到了每个bag中所有句子的表示。最后输出首先将这个向量与relation matrix做一个相似度计算后送入softmax归一化成概率: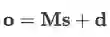
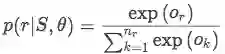
【注意】 在模型的test阶段,由于bag并没有给出的标签,因此在attention计算过程与train阶段不一样。处理方式为:对每一个relation,都做一遍上述的Selective Attention操作得到每个relation的得分,最后预测的结果就是取max就好啦。但是这样做会导致inference阶段会比较慢。
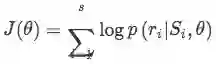
试验分析
数据集选取的是NYT,评价指标使用P@N

CODE HERE
4. Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks(Jiang/Coling 2016)
这篇文章主要是先分析了PCNN模型的缺陷,然后提出了几点改进方案:
at-least-once assumption假设太强,仅仅选取每个bag中的一个句子会丢失很多信息;解决方案是对bag内所有的sentence之间做max-pooling操作,可以提取出instance之间的隐藏关联;
single-label learning problem:在数据集中有大约18.3%的样本包含多种relation信息,设计了一种多标签损失函数,即使用sigmoid计算每一个类别的概率,然后判断该bag是否可能包含该类别。
基于以上两点提出了multi-instance multi-label convolutional neural network (MIMLCNN), 模型整体框架如下

从上图可以看出,整个模型主要包括三块:
Sentence-level Feature Extraction
目的就是将bag中的所有instance表示成向量形式,这里采取的就是第2节的PCNN模型,一模一样。
Cross-sentence Max-pooling
这一部分的设计就是为了解决“at-least-one assumption”,文中提出另一种假设:
A relation holding between two entities can be either expressed explicitly or inferred implicitly from all sentences that mention these two entities.
做法也很直观,直接对所有instance的向量每一个维度取最大值: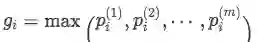
Multi-label Relation Modeling
上述过程得到的向量 g 经过一个全连接层计算每一个relation的score: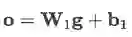
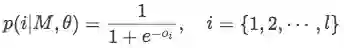
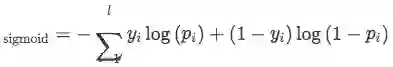
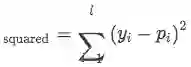
试验分析
实验数据集选取的是NYT10,评测标准选取了PR-曲线和P@N矩阵

5. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions(Ji/AAAI2017)
论文的主打的主要有两点:
第一点依然是针对Zeng的文章中提出的“at-least-one assumption”提出改进方案,采取的措施是对句子级别进行attention操作;
第二点是认为在知识库中对实体的描述也能反映很多的信息,建议将Entity Descriptions加入到模型中
模型的整体框架如下

APCNN Module
这一部分跟 Neural Relation Extraction with Selective Attention over Instances的工作非常像,唯一不同的地方在做attention时对query的选择不同。【Selective Attention】选择的是bag的真实标签,这样在训练时是没有问题的,不过在inference阶段由于样本bag没有标签,所以需要计算所有relation的得分选取最高的那一类,这样的话再test过程的计算量会很大。本文【Sentence-level Attention】采用的则是受word embedding特性的启发,认为relation的表示可以通过两个实体之间的运算得到:
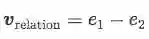
Entity Descriptions
到目前为止可以说没什么创新点,在这部分作者提出了将Entity Descriptions的信息融入模型,可以更好的帮助最后的relation判断。其实现也很简单,
输入为entity的word embedding,通过一层简单的CNN+max-pooling得到description的向量表示
文中提出的一个约束是:尽可能使得前面得到的entity的word embedding 与 这里得到的 entity 的 description embedding 接近,这样的动机很简单,就是将entity的描述信息融入到模型中,这部分的LOSS直接使用二范距离
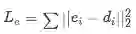
Loss Function
APCNN阶段的损失函数为:
Entity Dscriptions阶段的损失函数为:
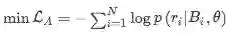
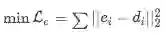
所以最终整体的损失函数为:
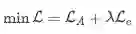
试验分析及小结
数据集和评价指标还是那些

在attention过程对relation embedding的处理采用了TransE的思路,可以说非常具有说服力
另外加入的实体描述建模也可以更有效地为模型融入更多信息,同时还会加强entity向量表示的准确性。
相关文章:
【论文】Awesome Relation Classification Paper(关系分类)(PART I)
【论文】Awesome Relation Classification Paper(关系分类)(PART II)
原文链接:
本文由作者原创授权AINLP首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。


