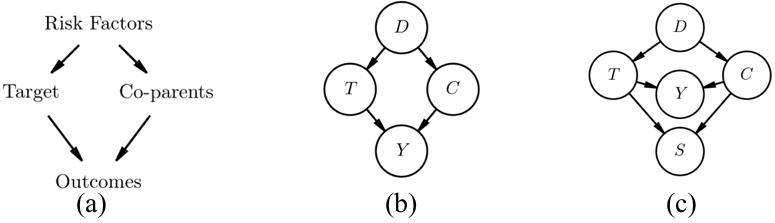
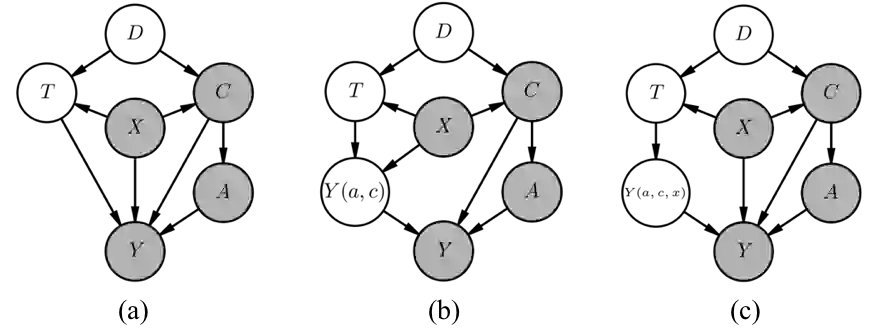
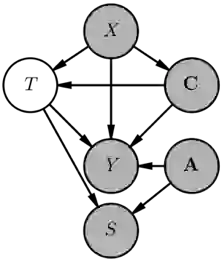
Predictive models can fail to generalize from training to deployment environments because of dataset shift, posing a threat to model reliability and the safety of downstream decisions made in practice. Instead of using samples from the target distribution to reactively correct dataset shift, we use graphical knowledge of the causal mechanisms relating variables in a prediction problem to proactively remove relationships that do not generalize across environments, even when these relationships may depend on unobserved variables (violations of the "no unobserved confounders" assumption). To accomplish this, we identify variables with unstable paths of statistical influence and remove them from the model. We also augment the causal graph with latent counterfactual variables that isolate unstable paths of statistical influence, allowing us to retain stable paths that would otherwise be removed. Our experiments demonstrate that models that remove vulnerable variables and use estimates of the latent variables transfer better, often outperforming in the target domain despite some accuracy loss in the training domain.
翻译:预测模型可能无法概括从培训到部署环境,因为数据集转换,对模型可靠性和实践中下游决策的安全性构成威胁。我们不使用目标分布样本到反应性正确的数据集转换。我们不使用预测问题中与变量相关的因果机制的图形知识,而是主动消除在预测问题中与变量有关的因果机制,即使这些关系可能取决于未观察到的变量(“无未观测的混淆者”假设的违反情况 ) 。为了实现这一目标,我们找出具有不稳定统计影响路径的变量,并将这些变量从模型中去除。我们还用潜在反事实变量来增加因果图,这些变量将分离出不稳定的统计影响路径,使我们得以保留本可以删除的稳定路径。我们的实验表明,排除脆弱变量和使用潜在变量转移估计数的模型会更好,尽管培训领域出现某些准确损失,但这些模型往往在目标领域表现不佳。