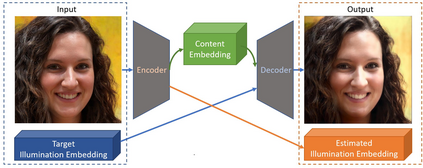
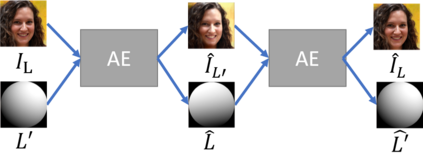
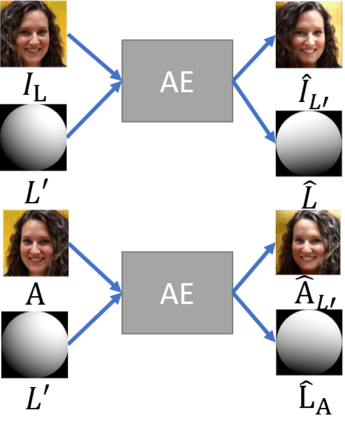
We propose a self-supervised method for image relighting of single view images in the wild. The method is based on an auto-encoder which deconstructs an image into two separate encodings, relating to the scene illumination and content, respectively. In order to disentangle this embedding information without supervision, we exploit the assumption that some augmentation operations do not affect the image content and only affect the direction of the light. A novel loss function, called spherical harmonic loss, is introduced that forces the illumination embedding to convert to a spherical harmonic vector. We train our model on large-scale datasets such as Youtube 8M and CelebA. Our experiments show that our method can correctly estimate scene illumination and realistically re-light input images, without any supervision or a prior shape model. Compared to supervised methods, our approach has similar performance and avoids common lighting artifacts.
翻译:我们建议一种自我监督的方法来点燃野生单一视图图像的图像光化。 该方法基于一个自动编码器, 该编码器将图像解构成两个不同的编码, 分别与现场光照和内容有关。 为了分解这种嵌入的信息, 我们利用这样的假设, 即某些增强操作不会影响图像内容, 只会影响光线的方向。 引入了一个叫作球体协调损失的新的损失函数, 迫使照明嵌入转换成球体协调矢量。 我们用诸如 Youtube 8M 和 CelebA 等大型数据集来培训我们的模型。 我们的实验显示, 我们的方法可以正确估计场光化和现实的重新光输入图像, 没有监督或先前的形状模型。 与受监督的方法相比, 我们的方法具有相似的性能, 并避免常用的照明工艺。