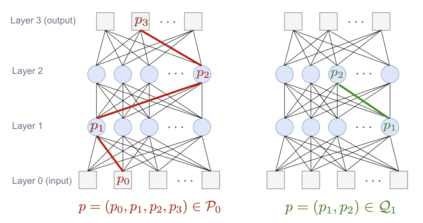
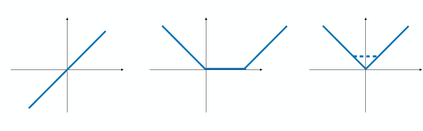
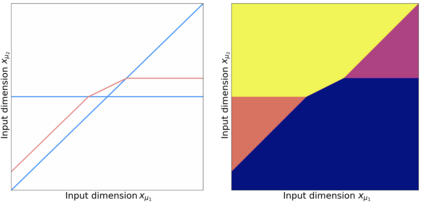
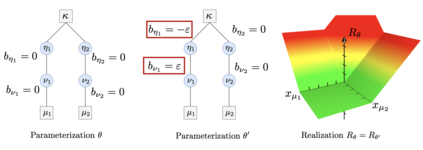
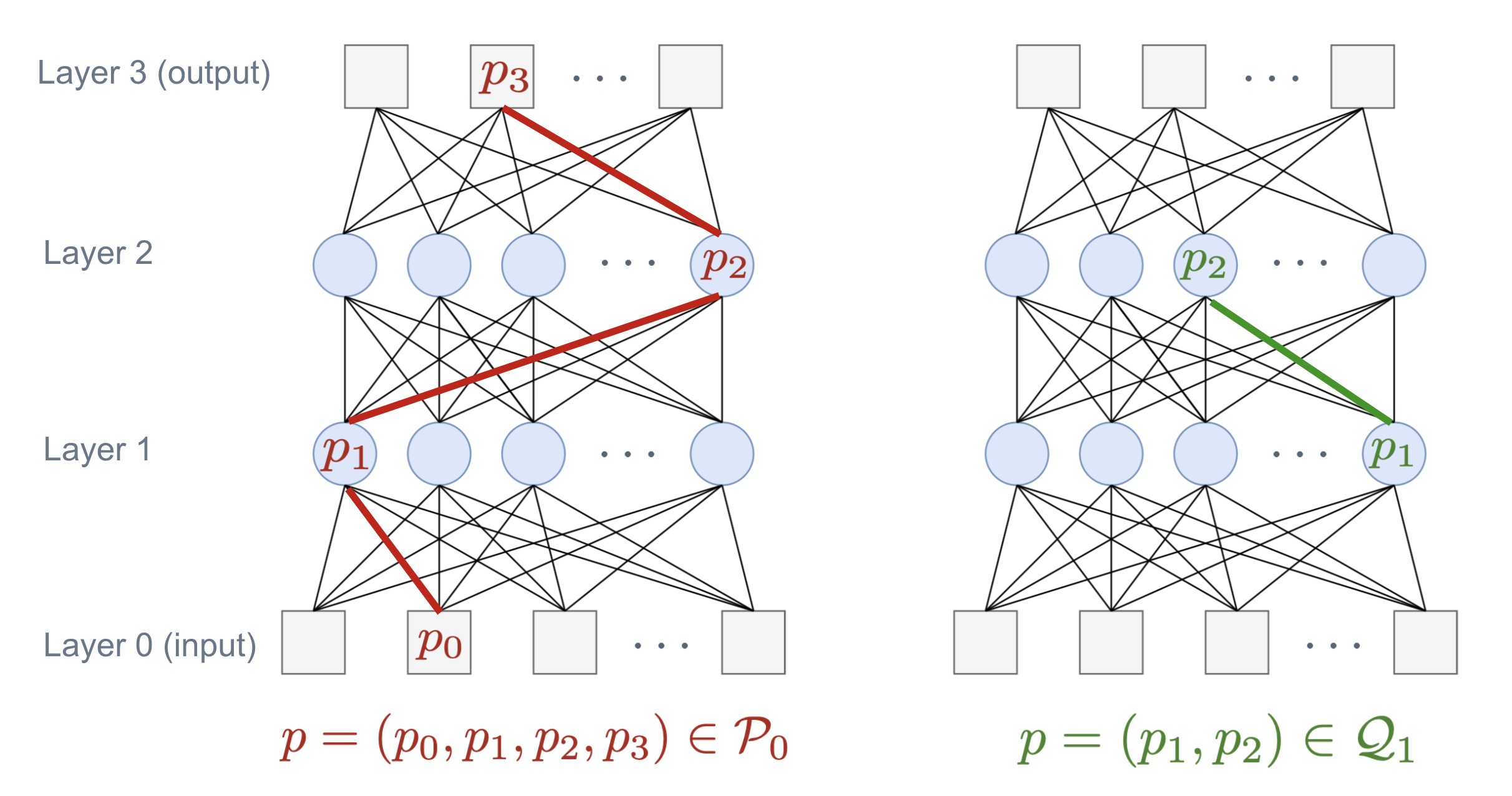
Neural networks with the Rectified Linear Unit (ReLU) nonlinearity are described by a vector of parameters $\theta$, and realized as a piecewise linear continuous function $R_{\theta}: x \in \mathbb R^{d} \mapsto R_{\theta}(x) \in \mathbb R^{k}$. Natural scalings and permutations operations on the parameters $\theta$ leave the realization unchanged, leading to equivalence classes of parameters that yield the same realization. These considerations in turn lead to the notion of identifiability -- the ability to recover (the equivalence class of) $\theta$ from the sole knowledge of its realization $R_{\theta}$. The overall objective of this paper is to introduce an embedding for ReLU neural networks of any depth, $\Phi(\theta)$, that is invariant to scalings and that provides a locally linear parameterization of the realization of the network. Leveraging these two key properties, we derive some conditions under which a deep ReLU network is indeed locally identifiable from the knowledge of the realization on a finite set of samples $x_{i} \in \mathbb R^{d}$. We study the shallow case in more depth, establishing necessary and sufficient conditions for the network to be identifiable from a bounded subset $\mathcal X \subseteq \mathbb R^{d}$.
翻译:使用校正线性单位( ReLU) 的神经网络不线性由参数矢量 $\theta$来描述, 并将其作为一个小线性连续函数 $R ⁇ theta}: x\ in\mathbbR ⁇ d}\mapsto R ⁇ theta}(x)\ in\mathbbr R ⁇ k}(x)\ in\mathbr\\\k}。 参数上的自然缩放和调整操作使实现保持不变, 导致对参数的等值类别, 从而产生相同的实现。 这些考虑因素反过来又导致识别性概念 -- -- 从唯一了解其实现情况后恢复( 等值类) $\\theta} : xxxxxxxxxx 的恢复能力(等值) 。 本文的总目标是为RLU 任何深度的内线性网络引入嵌嵌入, $\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\