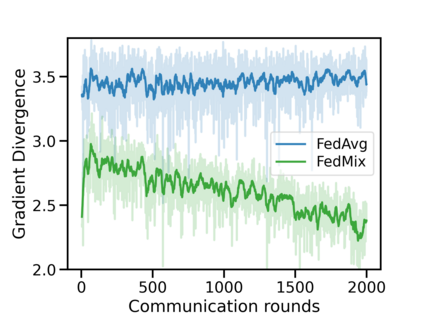
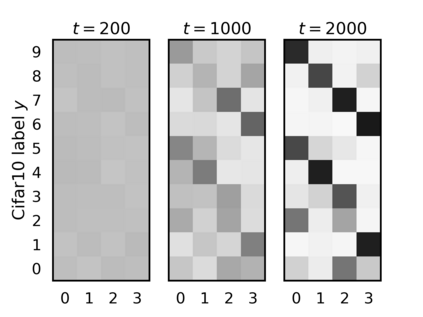
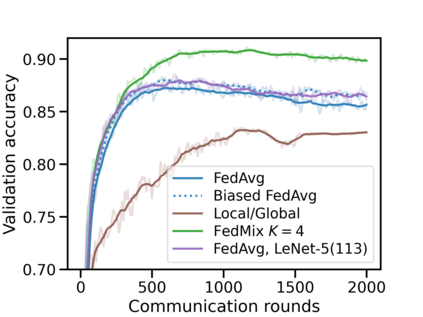
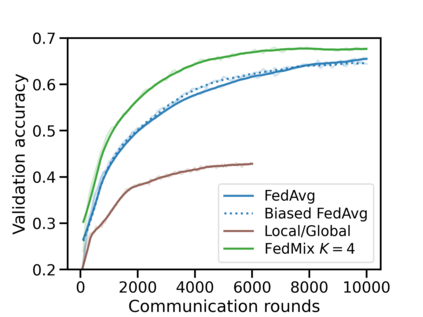
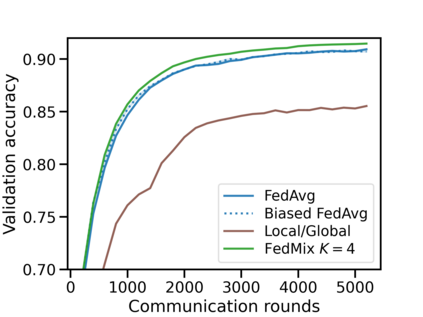
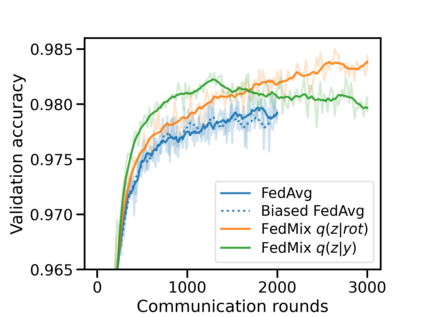
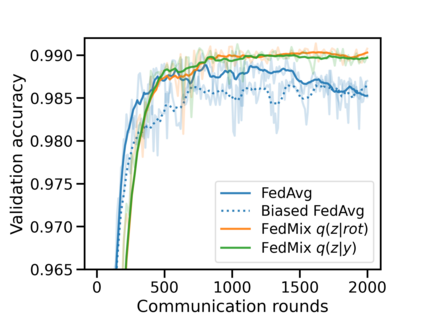
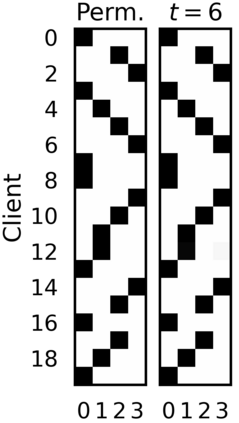
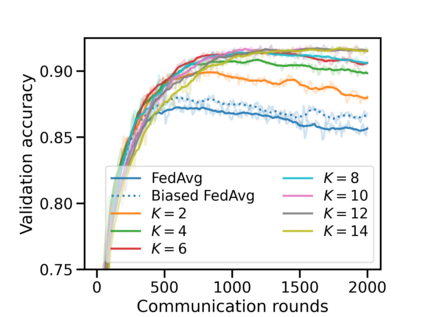
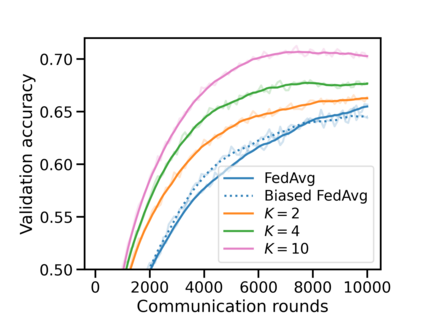
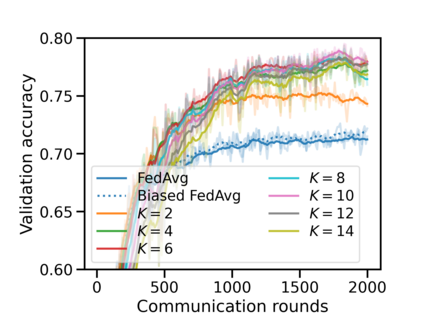
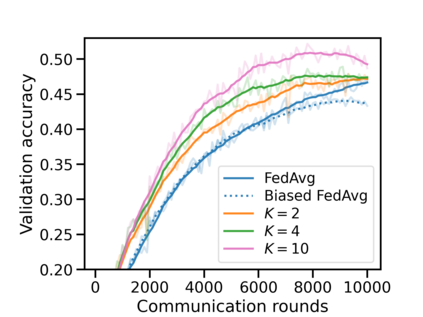
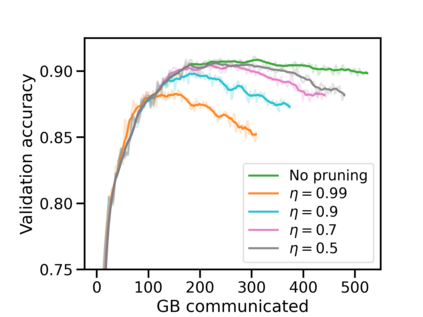
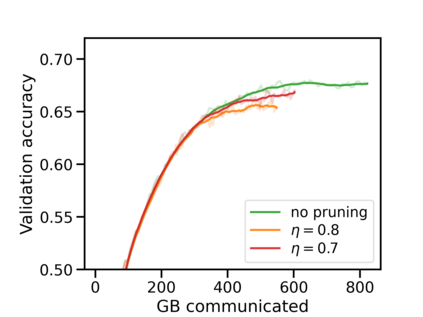
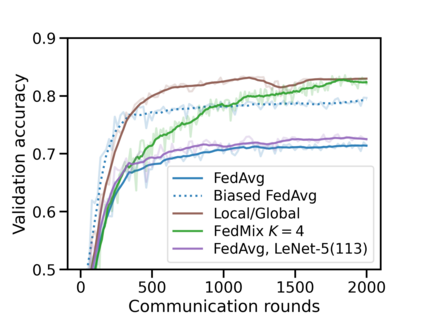
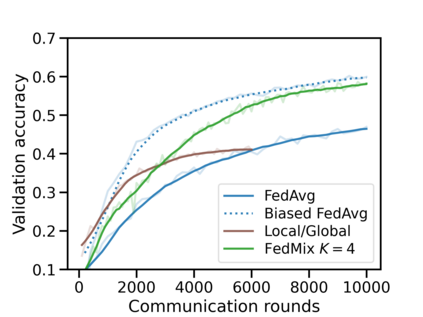
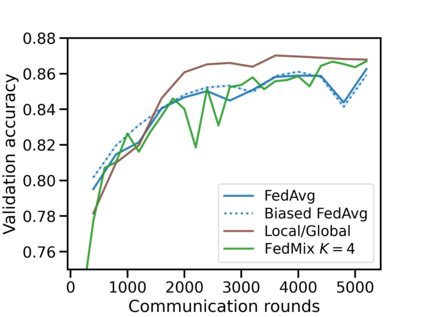
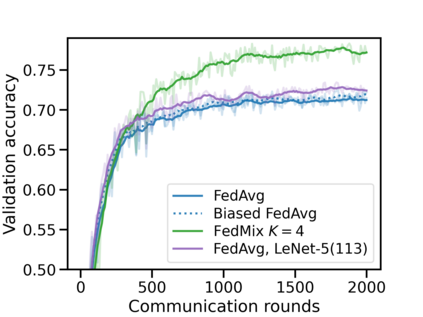
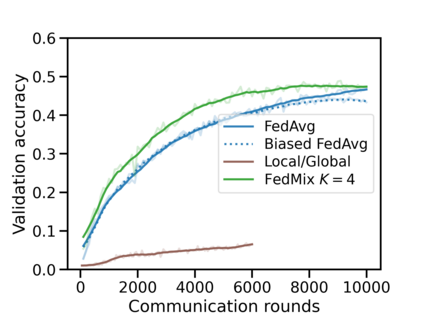
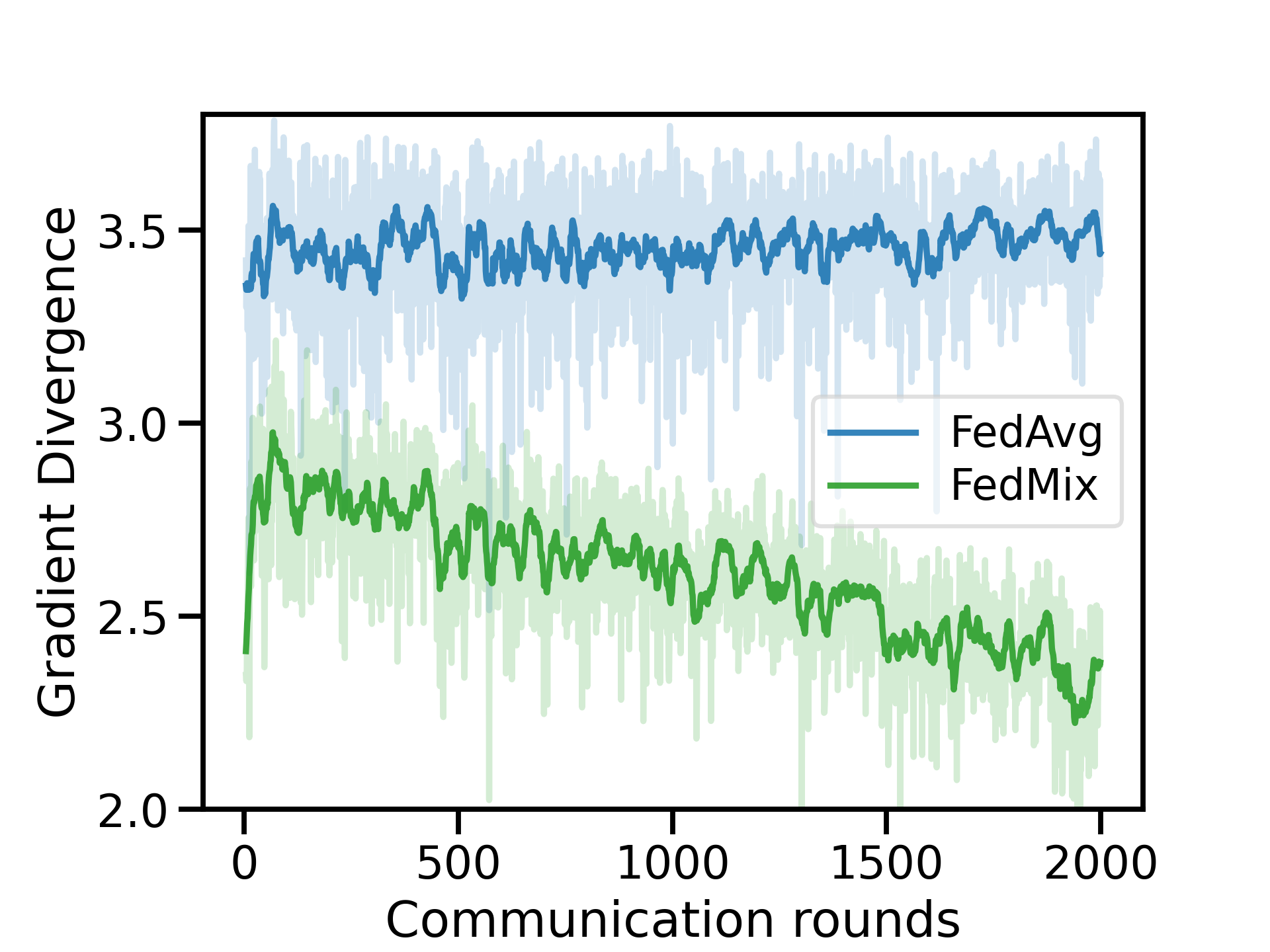
Federated learning (FL) has emerged as the predominant approach for collaborative training of neural network models across multiple users, without the need to gather the data at a central location. One of the important challenges in this setting is data heterogeneity, i.e. different users have different data characteristics. For this reason, training and using a single global model might be suboptimal when considering the performance of each of the individual user's data. In this work, we tackle this problem via Federated Mixture of Experts, FedMix, a framework that allows us to train an ensemble of specialized models. FedMix adaptively selects and trains a user-specific selection of the ensemble members. We show that users with similar data characteristics select the same members and therefore share statistical strength while mitigating the effect of non-i.i.d data. Empirically, we show through an extensive experimental evaluation that FedMix improves performance compared to using a single global model across a variety of different sources of non-i.i.d.-ness.
翻译:联邦学习(FL)已成为在多个用户之间合作培训神经网络模型的主要方法,无需在中心地点收集数据。这一环境的重要挑战之一是数据异质性,即不同用户具有不同的数据特征。因此,在考虑每个用户的数据的性能时,培训和使用单一的全球模型可能不尽如人意。在这项工作中,我们通过专家联合会FedMix(FedMix)处理这一问题。FedMix(FedMix)是一个框架,使我们能够培训一组专门模型。FedMix(FedMix)是适应性选择,并培训一个针对用户的组合成员选择。我们显示,具有类似数据特征的用户选择相同的成员,因此在减少非i.i.d数据的效果的同时分享统计力量。我们通过广泛的实验评估表明,FedMix(FedMix)改进了业绩,而不是使用各种非i.i.i.d.ness的单一全球模型。