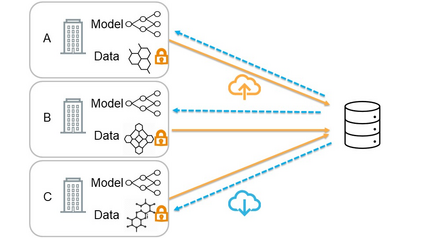
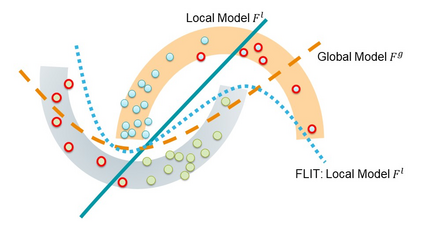
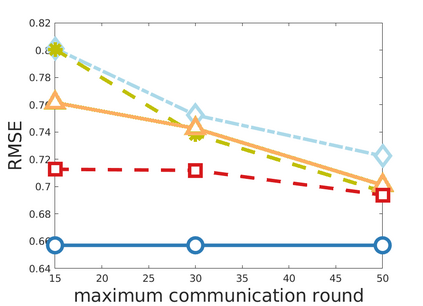
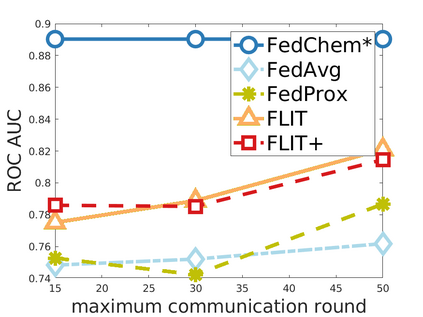
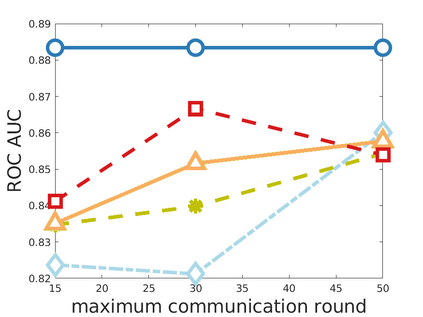
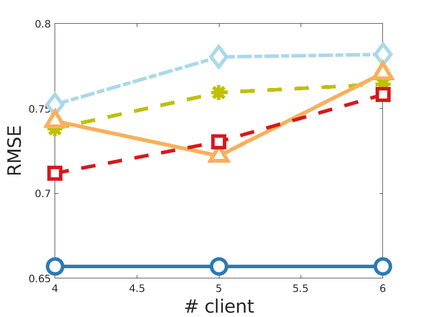
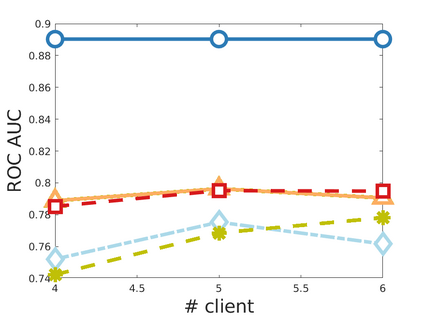
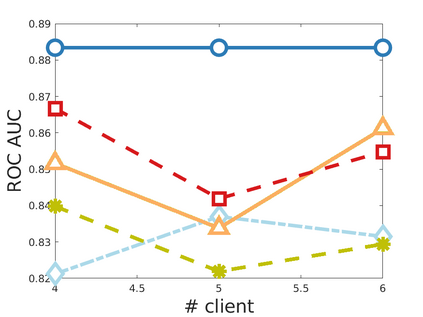
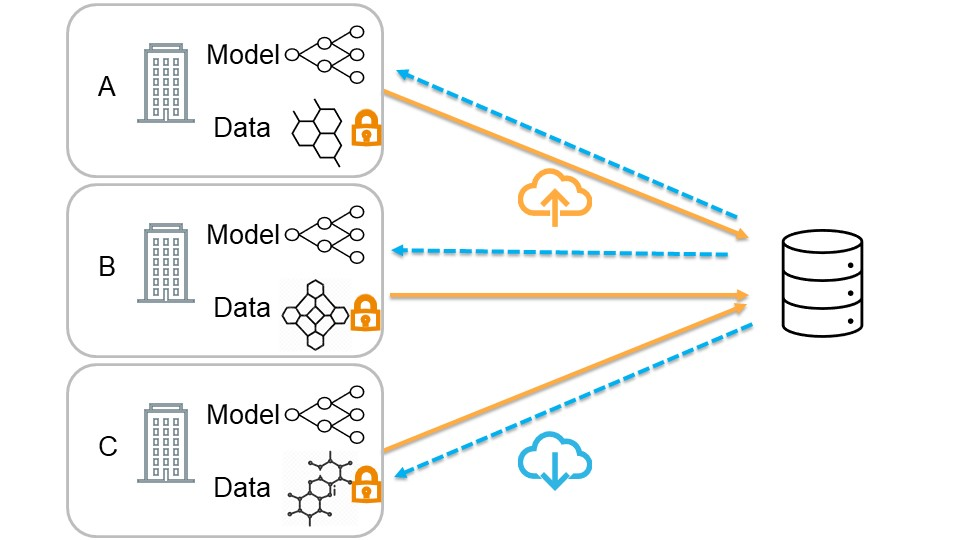
Chemistry research has both high material and computational costs to conduct experiments. Institutions thus consider chemical data to be valuable and there have been few efforts to construct large public datasets for machine learning. Another challenge is that different intuitions are interested in different classes of molecules, creating heterogeneous data that cannot be easily joined by conventional distributed training. In this work, we introduce federated heterogeneous molecular learning to address these challenges. Federated learning allows end-users to build a global model collaboratively while preserving the training data distributed over isolated clients. Due to the lack of related research, we first simulate a federated heterogeneous benchmark called FedChem. FedChem is constructed by jointly performing scaffold splitting and Latent Dirichlet Allocation on existing datasets. Our results on FedChem show that significant learning challenges arise when working with heterogeneous molecules. We then propose a method to alleviate the problem, namely Federated Learning by Instance reweighTing (FLIT). FLIT can align the local training across heterogeneous clients by improving the performance for uncertain samples. Comprehensive experiments conducted on our new benchmark FedChem validate the advantages of this method over other federated learning schemes. FedChem should enable a new type of collaboration for improving AI in chemistry that mitigates concerns about valuable chemical data.
翻译:进行实验所需的材料成本和计算成本都很高。因此,各机构认为化学数据是有价值的,而且很少努力为机器学习建造大型公共数据集。另一个挑战是,不同直觉对不同的分子类别感兴趣,产生不同的数据,而传统的分布式培训无法轻易结合这些数据。在这项工作中,我们引入了联结的多元分子学习,以应对这些挑战。联邦学习允许终端用户合作建立一个全球模型,同时保存在孤立客户之间分布的培训数据。由于缺乏相关的研究,我们首次模拟了一个名为FedChem的混合混合基准。FedChem是通过在现有的数据集上联合进行松散式分裂和冷淡的dirichlet分配建造的。我们在Fedchem的研究结果表明,在与混合分子合作时会出现重大的学习挑战。我们然后提出一个缓解问题的方法,即通过时间相邻(FLIT),通过改进不确定样本的性能来协调各不同客户的当地培训。我们新基准的FedChem(Fedchem)验证了该方法在降低化学特性方面其他宝贵计划方面的优势。FedChem(Fedchem)应该使ACT(Fedchem)能够改善数据类型合作。