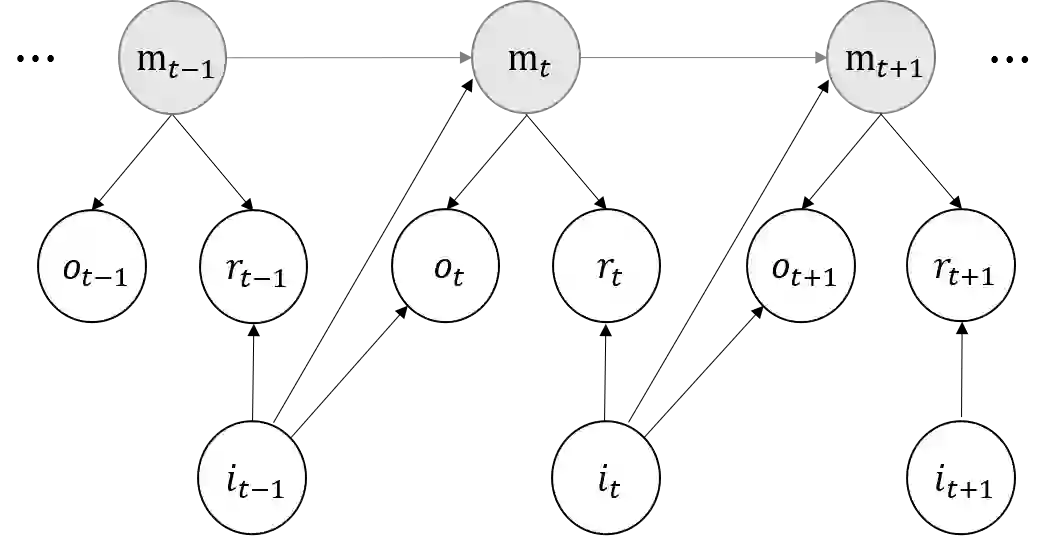
We study the model-based undiscounted reinforcement learning for partially observable Markov decision processes (POMDPs). The oracle we consider is the optimal policy of the POMDP with a known environment in terms of the average reward over an infinite horizon. We propose a learning algorithm for this problem, building on spectral method-of-moments estimations for hidden Markov models, the belief error control in POMDPs and upper-confidence-bound methods for online learning. We establish a regret bound of $O(T^{2/3}\sqrt{\log T})$ for the proposed learning algorithm where $T$ is the learning horizon. This is, to the best of our knowledge, the first algorithm achieving sublinear regret with respect to our oracle for learning general POMDPs.
翻译:我们研究了部分可见的Markov决定程序(POMDPs)基于模型的未贴现强化学习。我们认为,这是POMDP在无限地平线平均报酬方面已知环境的最佳政策。我们提出这一问题的学习算法,以隐藏的Markov模型的光谱方法估计、POMDPs中的信念错误控制以及在线学习的有上限信任的方法为基础。我们为拟议的学习算法确定了一个折合$O(T ⁇ 2/3 ⁇ sqrt_log T)的遗憾,其中$T是学习的地平线。我们最了解的是,这是我们学习一般POMDP的首个算法,对于我们学习一般POMDP的奥契机,实现了亚线性遗憾。