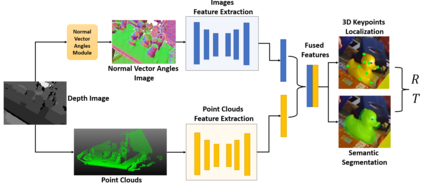
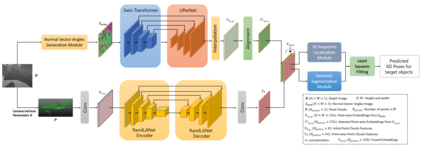
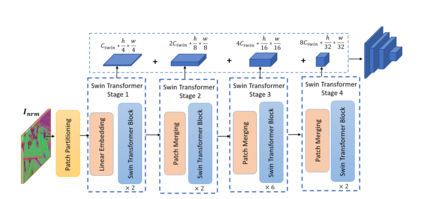
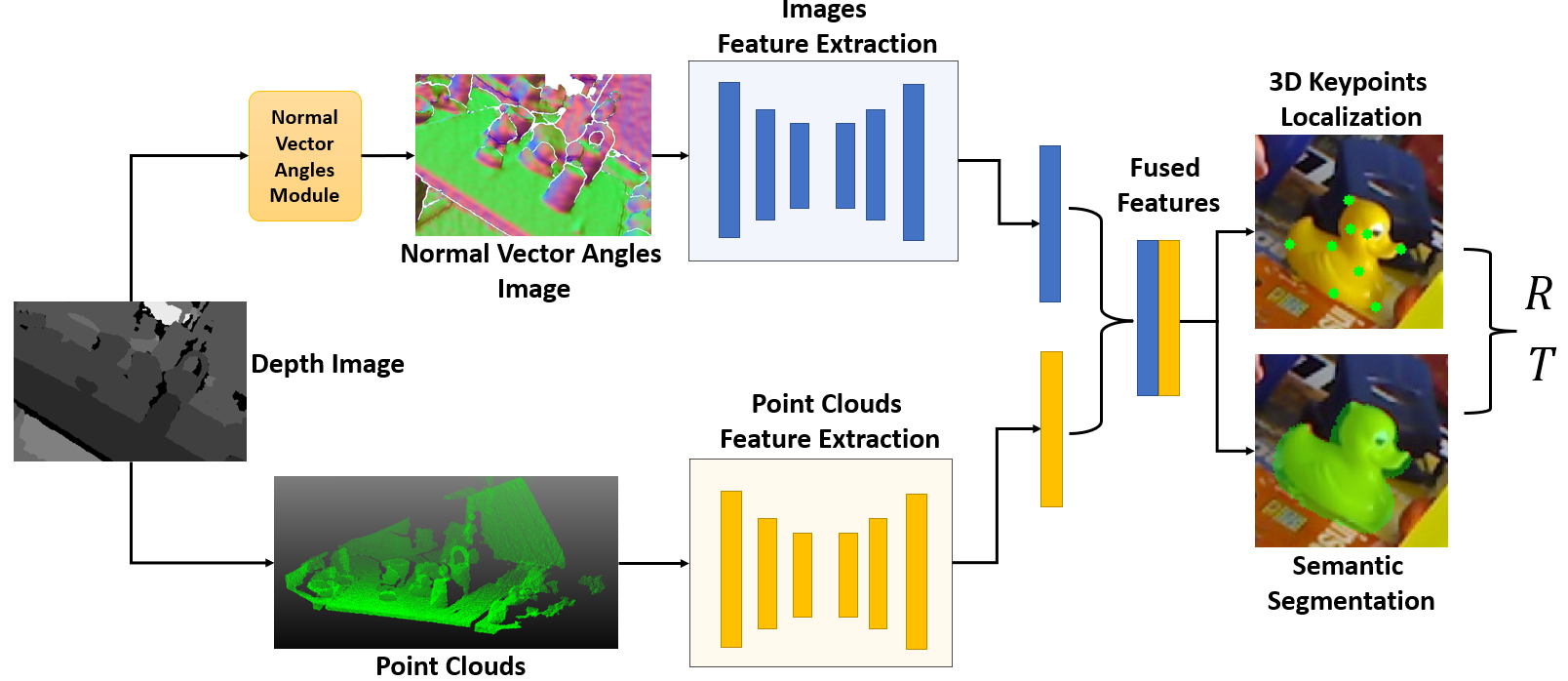
Accurately estimating the 6D pose of objects is crucial for many applications, such as robotic grasping, autonomous driving, and augmented reality. However, this task becomes more challenging in poor lighting conditions or when dealing with textureless objects. To address this issue, depth images are becoming an increasingly popular choice due to their invariance to a scene's appearance and the implicit incorporation of essential geometric characteristics. However, fully leveraging depth information to improve the performance of pose estimation remains a difficult and under-investigated problem. To tackle this challenge, we propose a novel framework called SwinDePose, that uses only geometric information from depth images to achieve accurate 6D pose estimation. SwinDePose first calculates the angles between each normal vector defined in a depth image and the three coordinate axes in the camera coordinate system. The resulting angles are then formed into an image, which is encoded using Swin Transformer. Additionally, we apply RandLA-Net to learn the representations from point clouds. The resulting image and point clouds embeddings are concatenated and fed into a semantic segmentation module and a 3D keypoints localization module. Finally, we estimate 6D poses using a least-square fitting approach based on the target object's predicted semantic mask and 3D keypoints. In experiments on the LineMod and Occlusion LineMod datasets, SwinDePose outperforms existing state-of-the-art methods for 6D object pose estimation using depth images. This demonstrates the effectiveness of our approach and highlights its potential for improving performance in real-world scenarios. Our code is at https://github.com/zhujunli1993/SwinDePose.
翻译:精确估计天体的 6D 形状对于许多应用来说至关重要, 例如 机器人抓取深度、 自主驱动和增强现实 。 然而, 这项任务在光亮条件差时或在处理无纹理天体时变得更具有挑战性 。 要解决这个问题, 深度图像正在变得日益流行的选择, 因为它们与场景的外观和基本几何特性的隐含结合不同。 但是, 充分利用深度信息来改善表面估测的性能仍然是一个困难和调查不足的问题 。 为了应对这一挑战, 我们提议了一个名为 SwinDePose 的新框架, 该框架仅使用从深度图像获得的几何度信息来实现准确的 6D 显示效果估计。 SwinDePose 首先计算一个在深度图像中定义的每个正常矢量矢量和三个协调轴之间的角度之间的角度。 由此产生的角度形成成图像, 由Swin变换器编码。 此外, 我们应用 RandLA- Net 来从点云中学习演示。 由此产生的图像和点云层嵌入的颜色是连接的, 并被输入到一个精确的天体- IM- D 方向的 Sdeal- dal- dal- dal- dal 。 在基于 Sloveal- dal- sal- 和 Ks 的 Sloveal- sal- sal- dal- sal- sal- sal- 和 sal- dal- dal- sal- sal- sal- sal- dal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- lad- sal- sal- sal- sal- sal- sal- sal- sald- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- salbalbalbal- sal- sal- sal- sal- mod- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal- sal-</s>