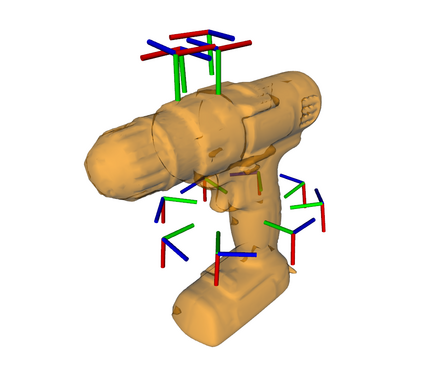
A Probabilistic Movement Primitive (ProMP) defines a distribution over trajectories with an associated feedback policy. ProMPs are typically initialized from human demonstrations and achieve task generalization through probabilistic operations. However, there is currently no principled guidance in the literature to determine how many demonstrations a teacher should provide and what constitutes a "good" demonstration for promoting generalization. In this paper, we present an active learning approach to learning a library of ProMPs capable of task generalization over a given space. We utilize uncertainty sampling techniques to generate a task instance for which a teacher should provide a demonstration. The provided demonstration is incorporated into an existing ProMP if possible, or a new ProMP is created from the demonstration if it is determined that it is too dissimilar from existing demonstrations. We provide a qualitative comparison between common active learning metrics; motivated by this comparison we present a novel uncertainty sampling approach named Greatest Mahalanobis Distance. We perform grasping experiments on a real KUKA robot and show our novel active learning measure achieves better task generalization with fewer demonstrations than a random sampling over the space.
翻译:概率运动(ProMP) 定义了轨道分布的分布和相关的反馈政策。ProMP 通常是从人类演示开始,通过概率操作实现任务一般化。然而,文献中目前没有原则性指导来确定教师应提供多少演示和什么是“好”演示,以促进概括化。在本文中,我们介绍了一种积极的学习方法,以学习一个能够对给定空间进行任务一般化的ProMP 图书馆。我们利用不确定的取样技术来产生一个教师应提供演示的任务实例。如果可能,所提供的演示被纳入现有的ProMP 中,或者如果确定与现有演示非常不同,则从演示中产生一个新的ProMP。我们根据这种比较,对共同的积极学习指标进行质量比较;我们提出了名为Greatest Mahalanobis 距离的新的不确定性抽样方法。我们在真正的 KUKA 机器人上进行实验,并展示我们新的积极学习措施比对空间进行随机抽样要少得多的任务一般化。