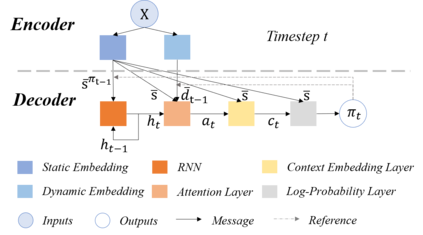
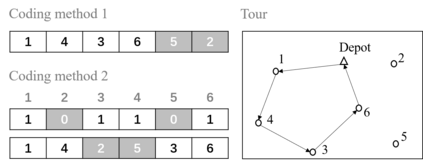
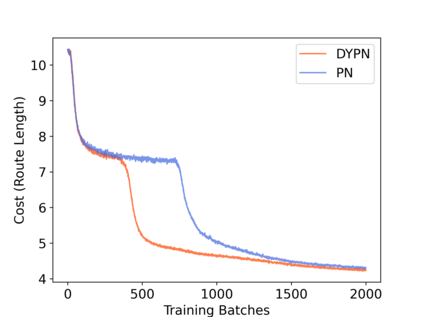
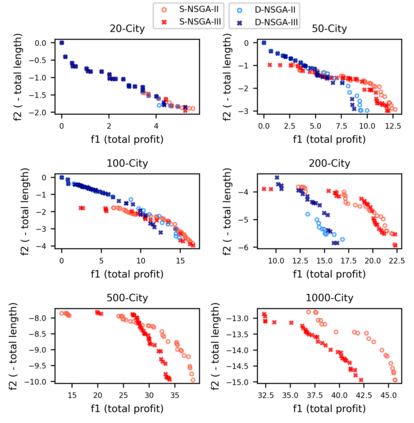
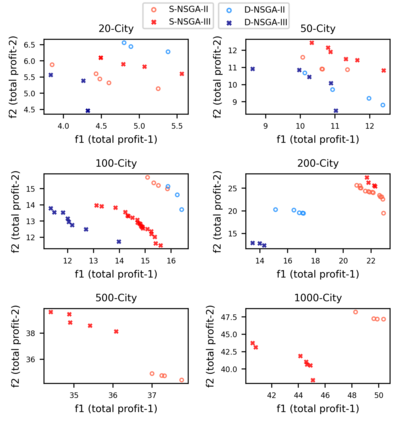
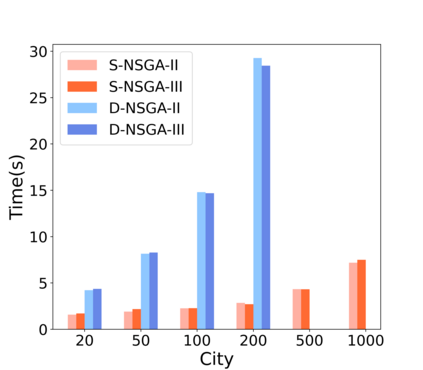
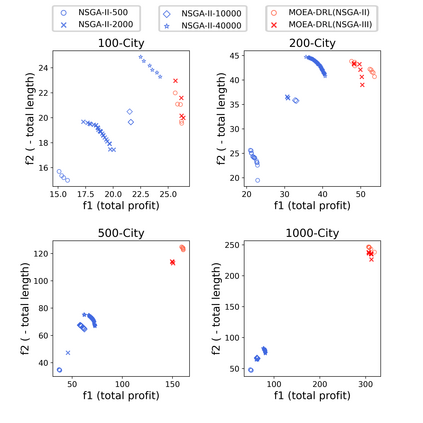
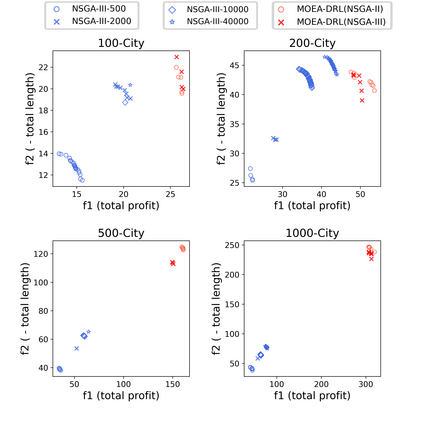
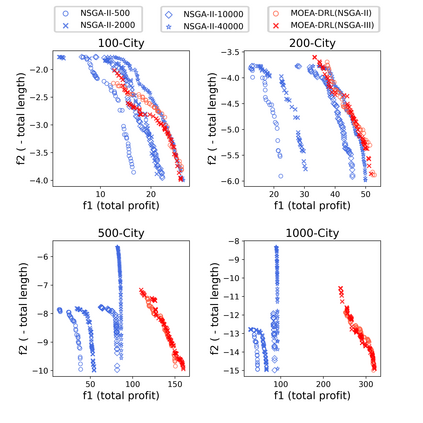
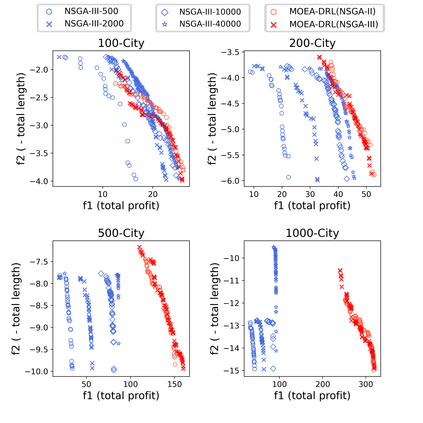
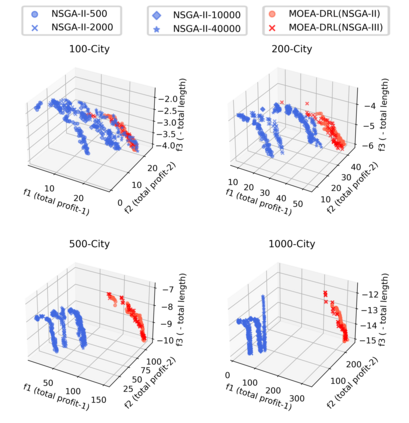
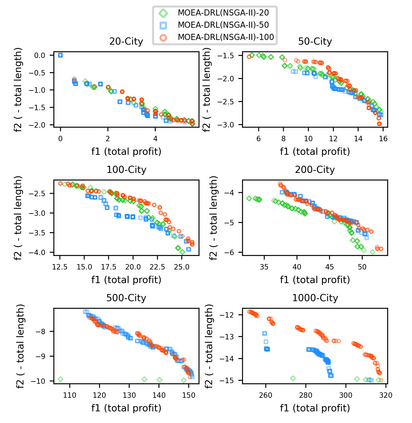
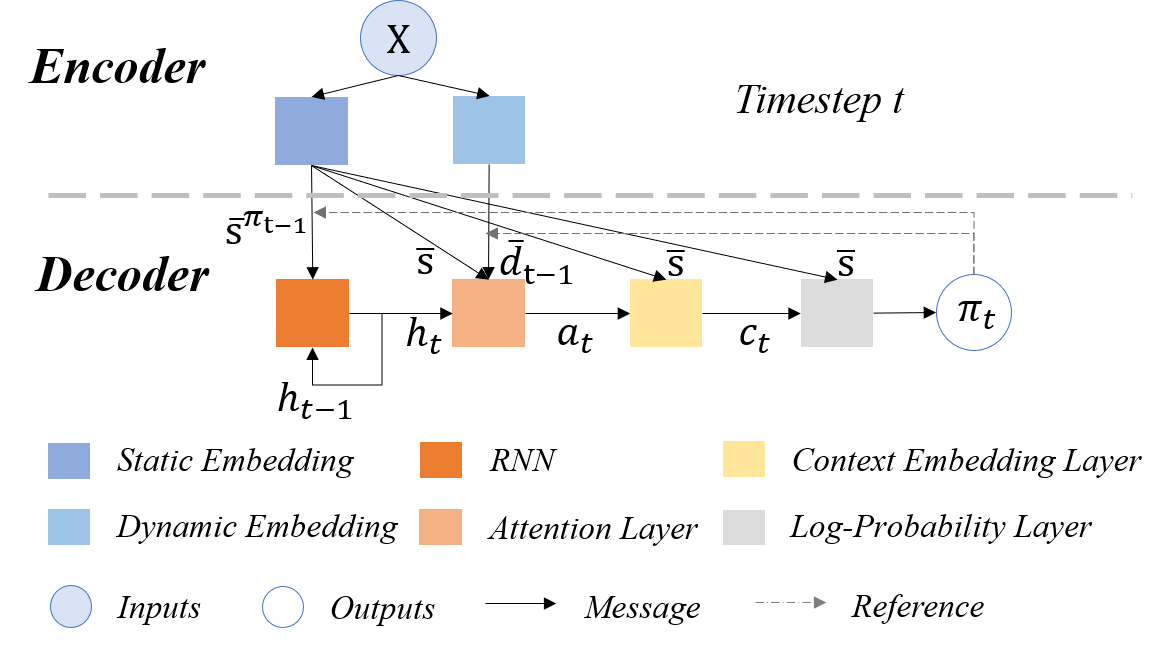
Multi-objective orienteering problems (MO-OPs) are classical multi-objective routing problems and have received a lot of attention in the past decades. This study seeks to solve MO-OPs through a problem-decomposition framework, that is, a MO-OP is decomposed into a multi-objective knapsack problem (MOKP) and a travelling salesman problem (TSP). The MOKP and TSP are then solved by a multi-objective evolutionary algorithm (MOEA) and a deep reinforcement learning (DRL) method, respectively. While the MOEA module is for selecting cities, the DRL module is for planning a Hamiltonian path for these cities. An iterative use of these two modules drives the population towards the Pareto front of MO-OPs. The effectiveness of the proposed method is compared against NSGA-II and NSGA-III on various types of MO-OP instances. Experimental results show that our method exhibits the best performance on almost all the test instances, and has shown strong generalization ability.
翻译:多重目标导向问题(MO-OPs)是典型的多目标路径问题,在过去几十年中受到了很多关注。本研究试图通过问题分解框架解决MO-OP问题,即MO-OP正在分解成一个多目标的Knapsack问题(MOKP)和一个流动销售商问题(TSP)。MOKP和TSP随后分别通过多目标进化算法(MOEA)和深入强化学习(DRL)方法加以解决。MOEA模块用于选择城市,而DRL模块用于规划这些城市的汉密尔顿式路径。这两个模块的反复使用将人口推向MO-OP的Pareto前方。拟议方法的有效性与NSGA-II和NSGA-III在各类MO-OP实例上进行比较。实验结果表明,我们的方法展示了几乎所有测试实例的最佳表现,并展示了强大的概括能力。