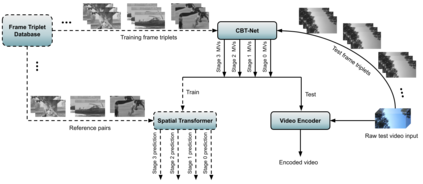
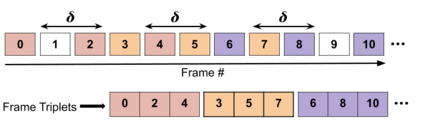
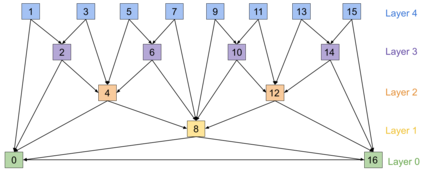
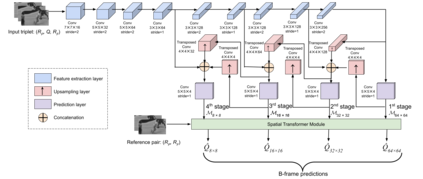
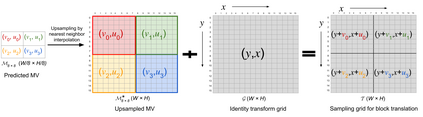
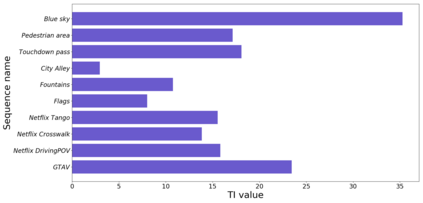
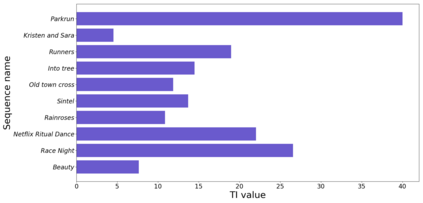
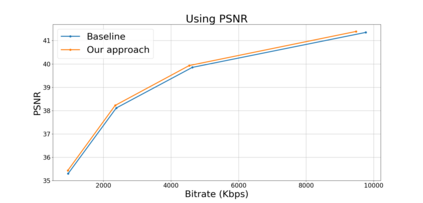
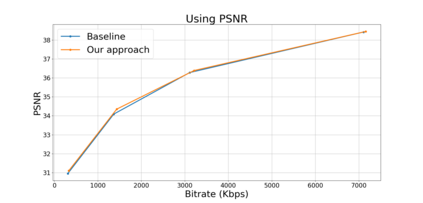
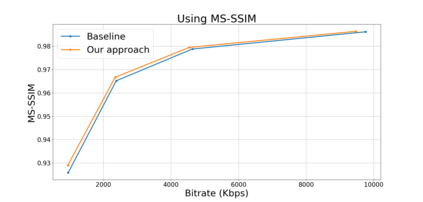
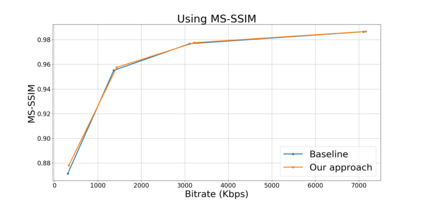
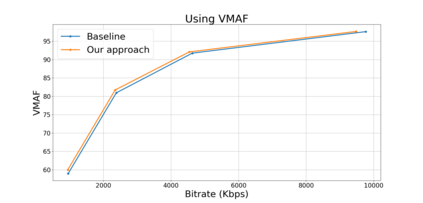
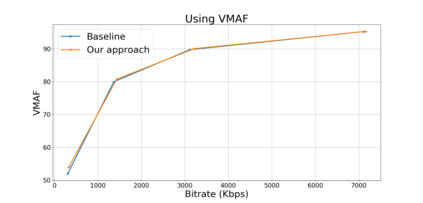
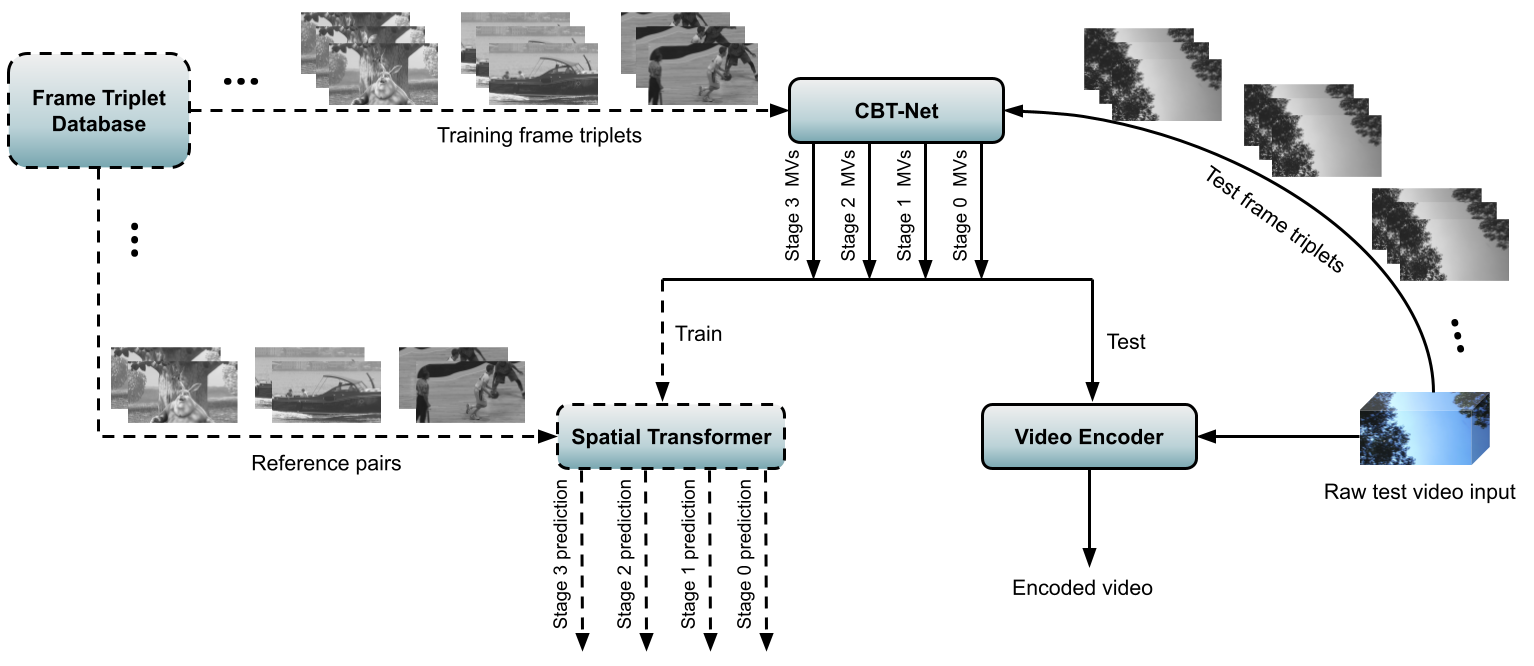
Block based motion estimation is integral to inter prediction processes performed in hybrid video codecs. Prevalent block matching based methods that are used to compute block motion vectors (MVs) rely on computationally intensive search procedures. They also suffer from the aperture problem, which can worsen as the block size is reduced. Moreover, the block matching criteria used in typical codecs do not account for the resulting levels of perceptual quality of the motion compensated pictures that are created upon decoding. Towards achieving the elusive goal of perceptually optimized motion estimation, we propose a search-free block motion estimation framework using a multi-stage convolutional neural network, which is able to conduct motion estimation on multiple block sizes simultaneously, using a triplet of frames as input. This composite block translation network (CBT-Net) is trained in a self-supervised manner on a large database that we created from publicly available uncompressed video content. We deploy the multi-scale structural similarity (MS-SSIM) loss function to optimize the perceptual quality of the motion compensated predicted frames. Our experimental results highlight the computational efficiency of our proposed model relative to conventional block matching based motion estimation algorithms, for comparable prediction errors. Further, when used to perform inter prediction in AV1, the MV predictions of the perceptually optimized model result in average Bjontegaard-delta rate (BD-rate) improvements of -1.70% and -1.52% with respect to the MS-SSIM and Video Multi-Method Assessment Fusion (VMAF) quality metrics, respectively as compared to the block matching based motion estimation system employed in the SVT-AV1 encoder.
翻译:以区块为基础的区块运动估计是混合视频代码化中执行的跨预测过程的组成部分。 用于计算块块运动矢量( MV) 的平面区块匹配基础方法依赖于计算密集搜索程序。 它们也存在孔径问题, 随着区块大小的缩小, 这一问题可能会恶化。 此外, 典型的区块匹配标准没有考虑到在解码时产生的运动补偿图片的感知质量。 为了实现概念优化运动估计这一难以捉摸的目标, 我们建议使用一个多阶段平流神经网络进行无搜索区块估计框架, 这个框架能够同时进行多块尺寸的运动估计, 使用三重框架作为输入。 这个复合区块翻译网络( CBT-Net) 以自我监督的方式在大型数据库中进行了培训, 该数据库是我们从公开提供的不受压缩的视频内容中创建的。 我们将多级结构相似性(MS- SSIMA) 损失功能化模型, 优化运动补偿预测框的感知质量。 我们的实验结果显示, 与常规预测的SMV1相比, B- 平均预测的计算中, 将S- 的系统- 系统- 系统- 系统- 系统- 比率比常规预测的S- 的预测,将S- 的S- 的系统- 的预测结果,将SVMVI- 的比比的系统- s- s- s- s- s- s- s- salvialvi) 的比 的 的 的 的 的 的 的预测比率, 的 的 的 的 的 的 的 的 用于的 的 的 的 的 的 的 的 的 的 的 的 和 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 和 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 和 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的