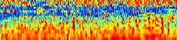
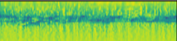
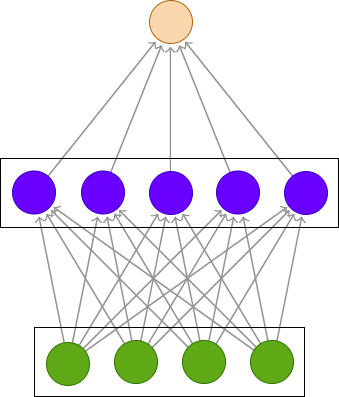
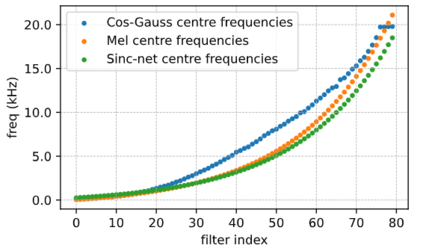
In this work, we propose a multi-head relevance weighting framework to learn audio representations from raw waveforms. The audio waveform, split into windows of short duration, are processed with a 1-D convolutional layer of cosine modulated Gaussian filters acting as a learnable filterbank. The key novelty of the proposed framework is the introduction of multi-head relevance on the learnt filterbank representations. Each head of the relevance network is modelled as a separate sub-network. These heads perform representation enhancement by generating weight masks for different parts of the time-frequency representation learnt by the parametric acoustic filterbank layer. The relevance weighted representations are fed to a neural classifier and the whole system is trained jointly for the audio classification objective. Experiments are performed on the DCASE2020 Task 1A challenge as well as the Urban Sound Classification (USC) tasks. In these experiments, the proposed approach yields relative improvements of 10% and 23% respectively for the DCASE2020 and USC datasets over the mel-spectrogram baseline. Also, the analysis of multi-head relevance weights provides insights on the learned representations.
翻译:在这项工作中,我们提出一个多头相关权重框架,以从原始波形中学习音频表达方式。音波形分为短期窗口,用1层卷发层的可学习过滤器处理。拟议框架的关键新颖之处是在所学的过滤库中引入多头相关性。每个相关网络的头部都以一个单独的子网络为模范。这些头部通过为模拟声波过滤库层所学的时间频率代表方式的不同部分生成重力遮罩来进行代表增强。相关权重表示方式被输入神经分类器,整个系统经过联合培训,以达到音频分类目标。在DCASE20任务1A挑战以及城市声音分类任务上进行了实验。在这些实验中,拟议的方法使DCASE20和USC在M光谱基线上的时间频率显示器分别实现了10%和23%的相对改进。此外,对多头相关性加权的分析提供了对所学表现方式的深刻见解。