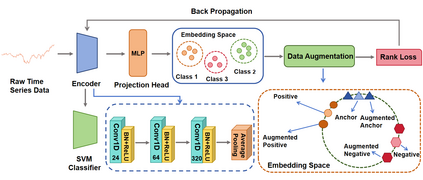
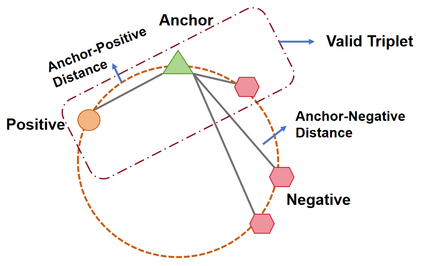
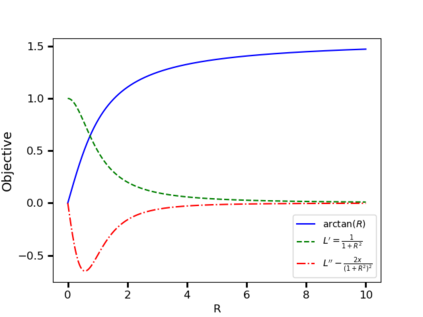
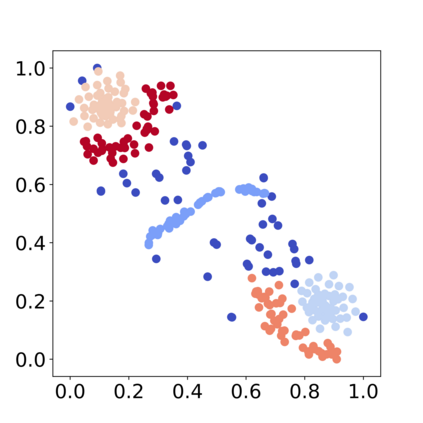
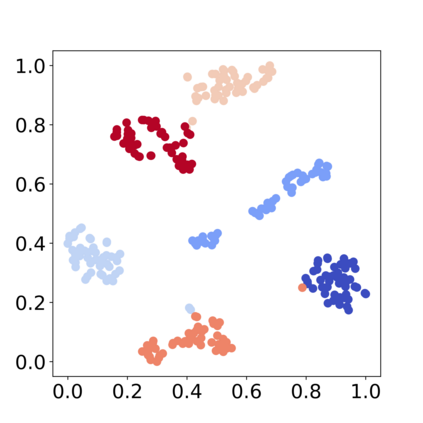
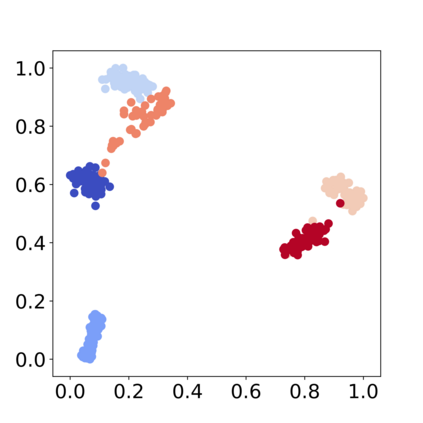
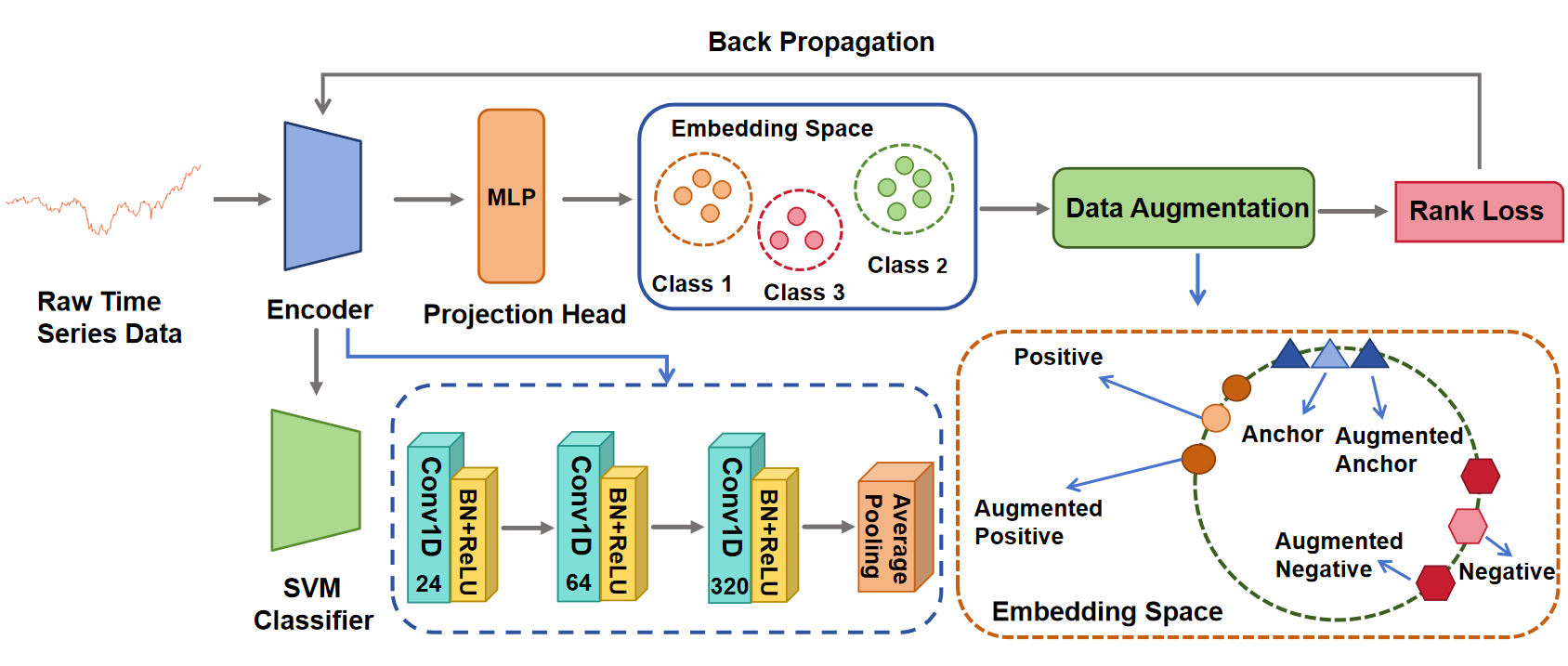
Recently, various contrastive learning techniques have been developed to categorize time series data and exhibit promising performance. A general paradigm is to utilize appropriate augmentations and construct feasible positive samples such that the encoder can yield robust and discriminative representations by mapping similar data points closer together in the feature space while pushing dissimilar data points farther apart. Despite its efficacy, the fine-grained relative similarity (e.g., rank) information of positive samples is largely ignored, especially when labeled samples are limited. To this end, we present Rank Supervised Contrastive Learning (RankSCL) to perform time series classification. Different from conventional contrastive learning frameworks, RankSCL augments raw data in a targeted way in the embedding space and adopts certain filtering rules to select more informative positive and negative pairs of samples. Moreover, a novel rank loss is developed to assign different weights for different levels of positive samples, enable the encoder to extract the fine-grained information of the same class, and produce a clear boundary among different classes. Thoroughly empirical studies on 128 UCR datasets and 30 UEA datasets demonstrate that the proposed RankSCL can achieve state-of-the-art performance compared to existing baseline methods.
翻译:暂无翻译