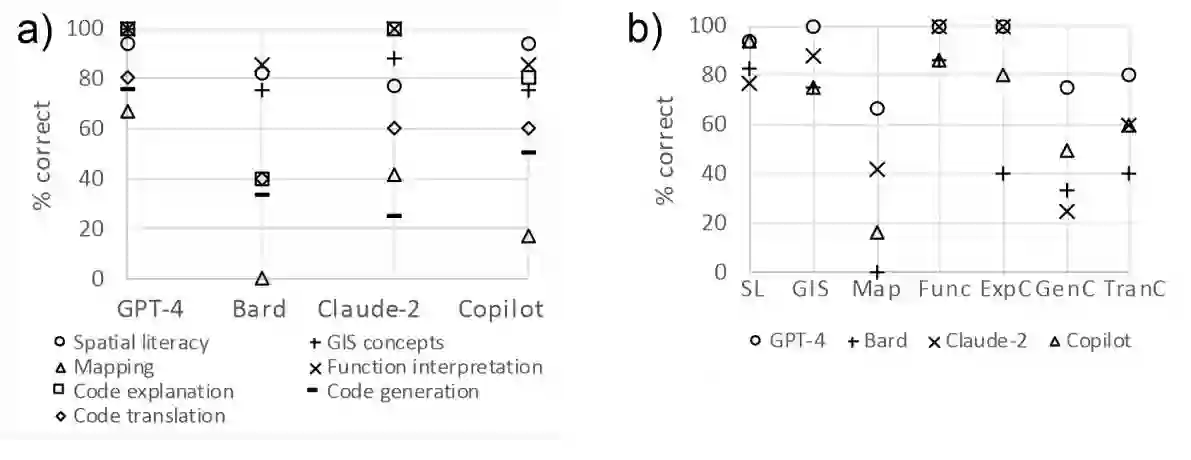
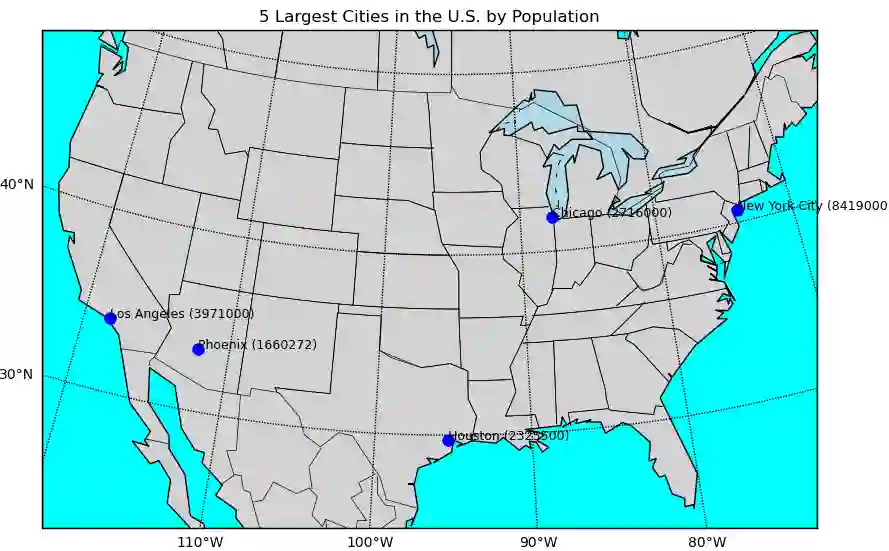
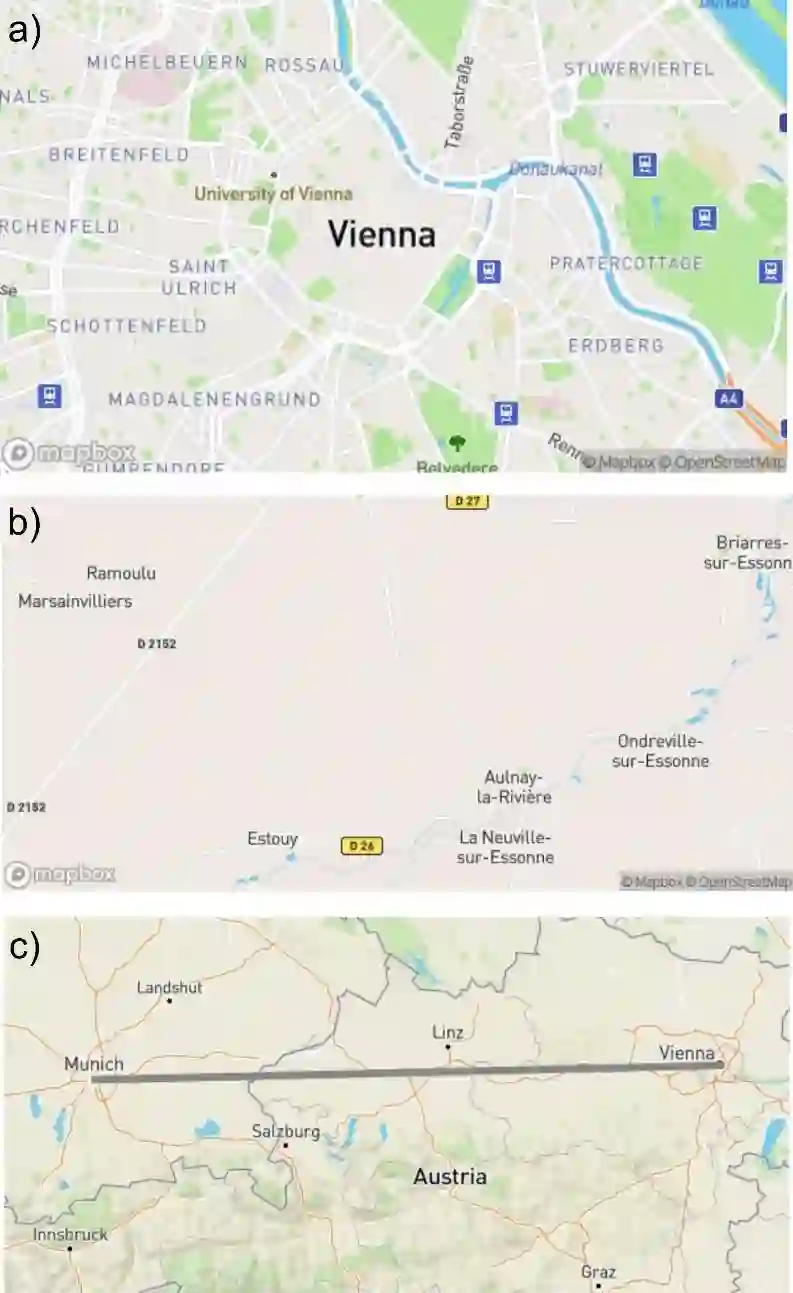
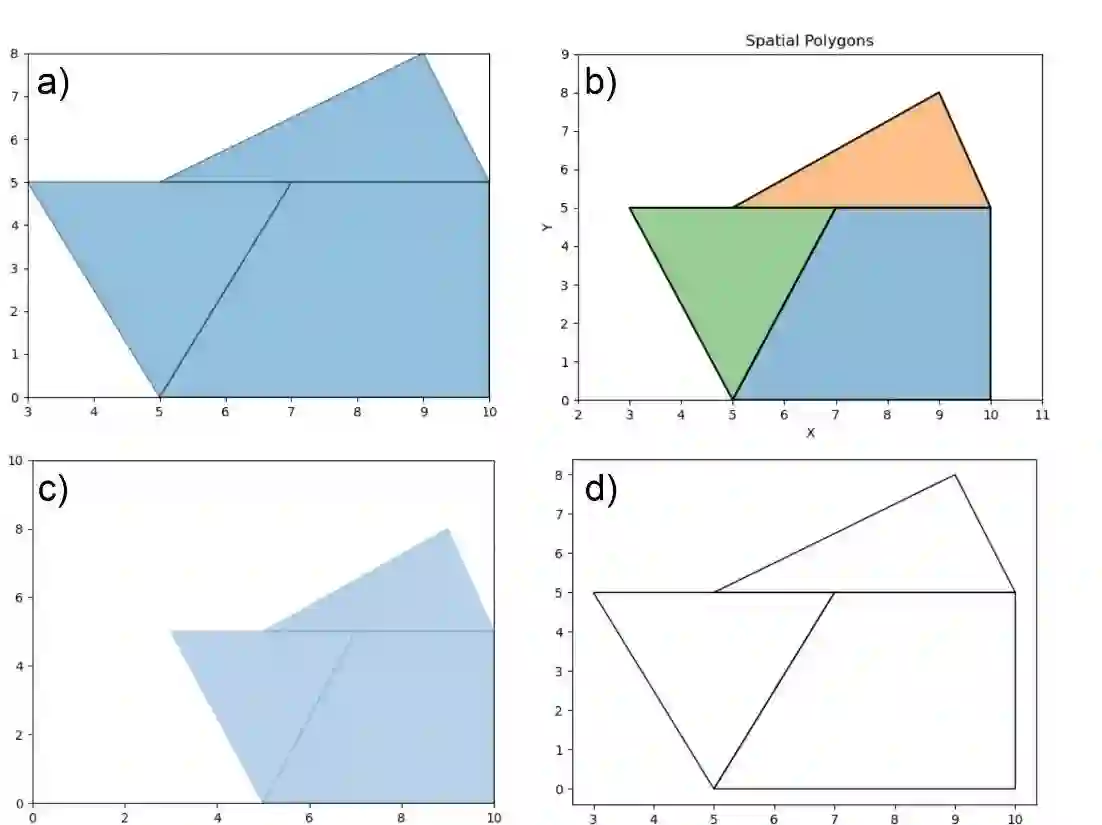
Generative AI including large language models (LLMs) have recently gained significant interest in the geo-science community through its versatile task-solving capabilities including coding, spatial computations, generation of sample data, time-series forecasting, toponym recognition, or image classification. So far, the assessment of LLMs for spatial tasks has primarily focused on ChatGPT, arguably the most prominent AI chatbot, whereas other chatbots received less attention. To narrow this research gap, this study evaluates the correctness of responses for a set of 54 spatial tasks assigned to four prominent chatbots, i.e., ChatGPT-4, Bard, Claude-2, and Copilot. Overall, the chatbots performed well on spatial literacy, GIS theory, and interpretation of programming code and given functions, but revealed weaknesses in mapping, code generation, and code translation. ChatGPT-4 outperformed other chatbots across most task categories.
翻译:暂无翻译