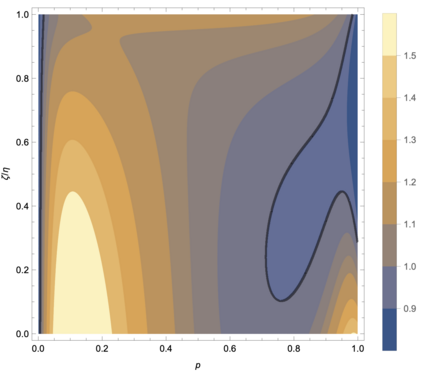
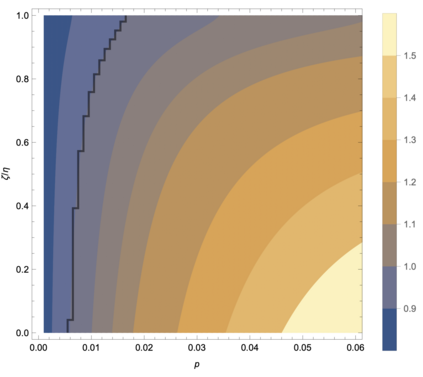
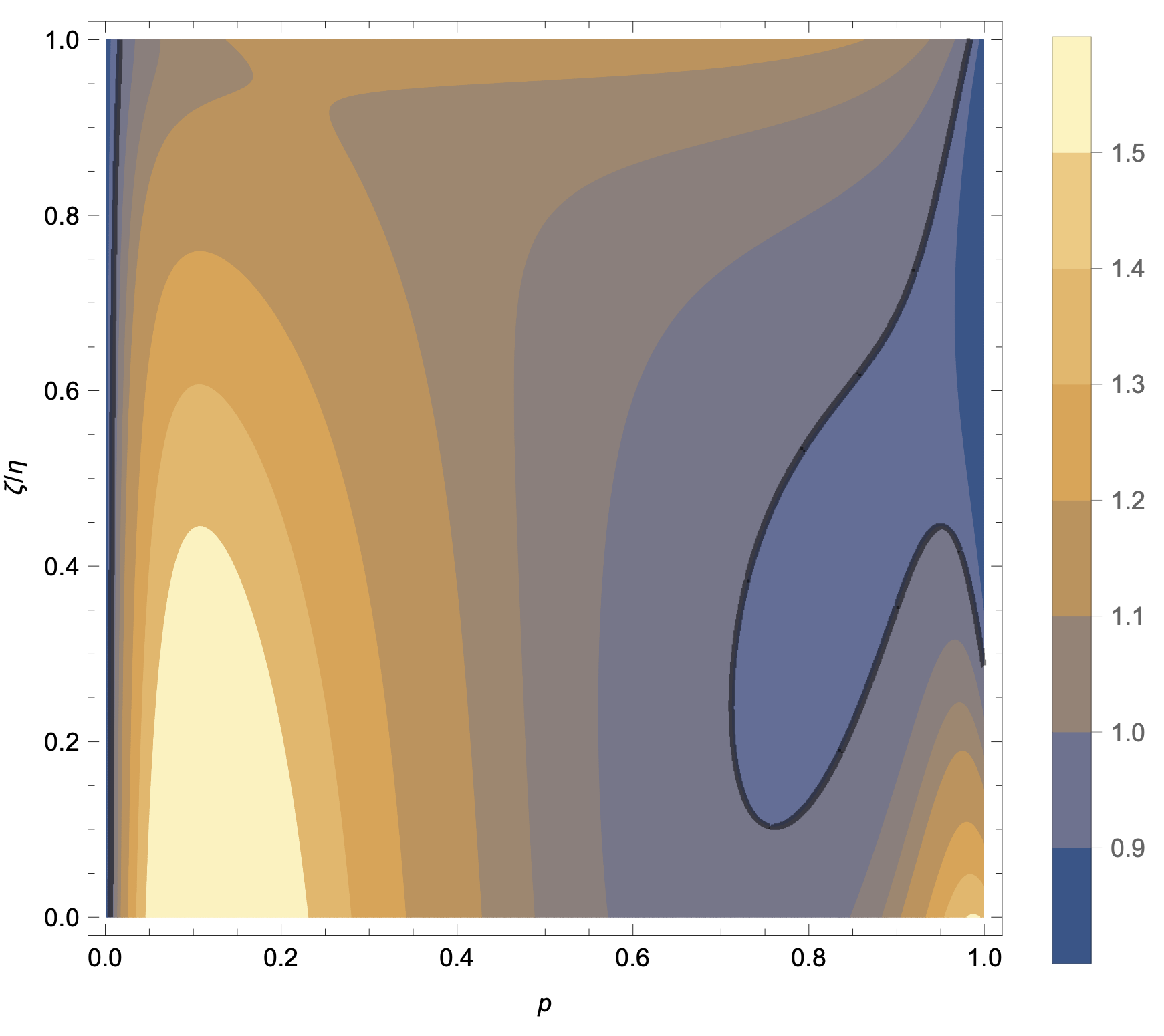
One of the distinguishing characteristics of modern deep learning systems is that they typically employ neural network architectures that utilize enormous numbers of parameters, often in the millions and sometimes even in the billions. While this paradigm has inspired significant research on the properties of large networks, relatively little work has been devoted to the fact that these networks are often used to model large complex datasets, which may themselves contain millions or even billions of constraints. In this work, we focus on this high-dimensional regime in which both the dataset size and the number of features tend to infinity. We analyze the performance of random feature regression with features $F=f(WX+B)$ for a random weight matrix $W$ and random bias vector $B$, obtaining exact formulae for the asymptotic training and test errors for data generated by a linear teacher model. The role of the bias can be understood as parameterizing a distribution over activation functions, and our analysis directly generalizes to such distributions, even those not expressible with a traditional additive bias. Intriguingly, we find that a mixture of nonlinearities can improve both the training and test errors over the best single nonlinearity, suggesting that mixtures of nonlinearities might be useful for approximate kernel methods or neural network architecture design.
翻译:现代深层次学习系统的一个显著特征是,它们通常使用使用神经网络结构,这些结构使用大量参数,往往以百万计,有时甚至以数十亿计。虽然这一模式激发了对大型网络特性的重要研究,但相对较少的工作是,这些网络往往用于模拟大型复杂数据集,而这些数据集本身可能包含数百万甚至数十亿个制约因素。在这项工作中,我们侧重于这种高维系统,其中数据集大小和特征数量往往不尽相同。我们分析随机重力矩阵($F=f(WX+B))的随机特征回归性能,用美元($W$)和随机偏向矢量($B$)来进行随机回归性回归性回归性回归性回归性回归性特征的性能,获得无损培训的精确公式和测试线性教师模型生成的数据的错误。这种偏差的作用可以被理解为对激活功能的分布进行参数的比较,我们的分析直接概括了这种分布,即使是那些不易表现为传统添加偏差的特性。我们发现,一种非线性特性混合物的混合物可以改进用于最佳设计非线性结构的模型的不精确度方法。