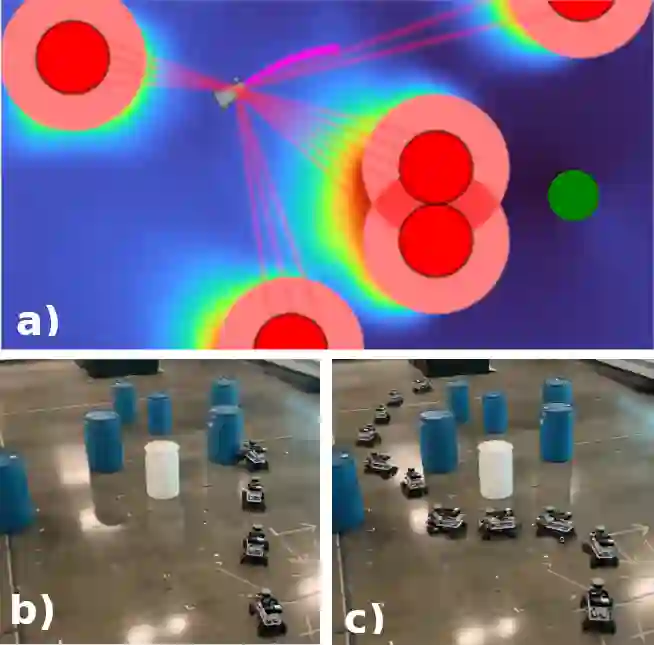
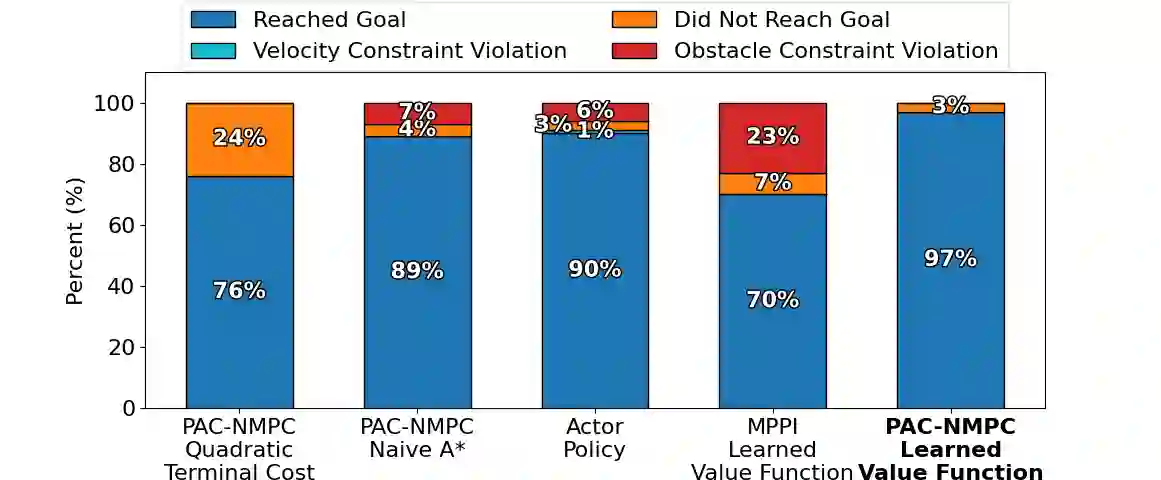
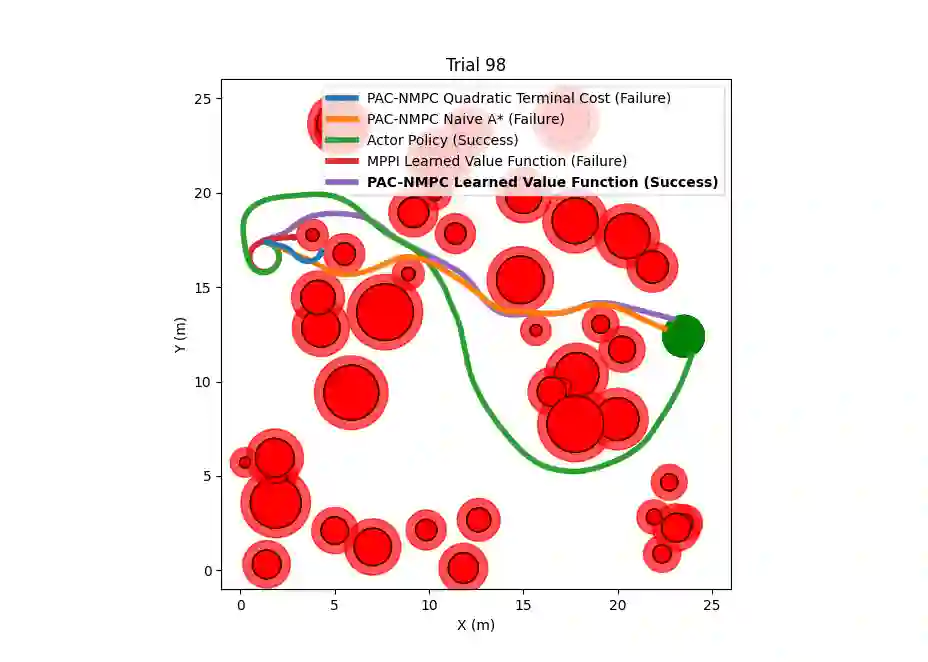
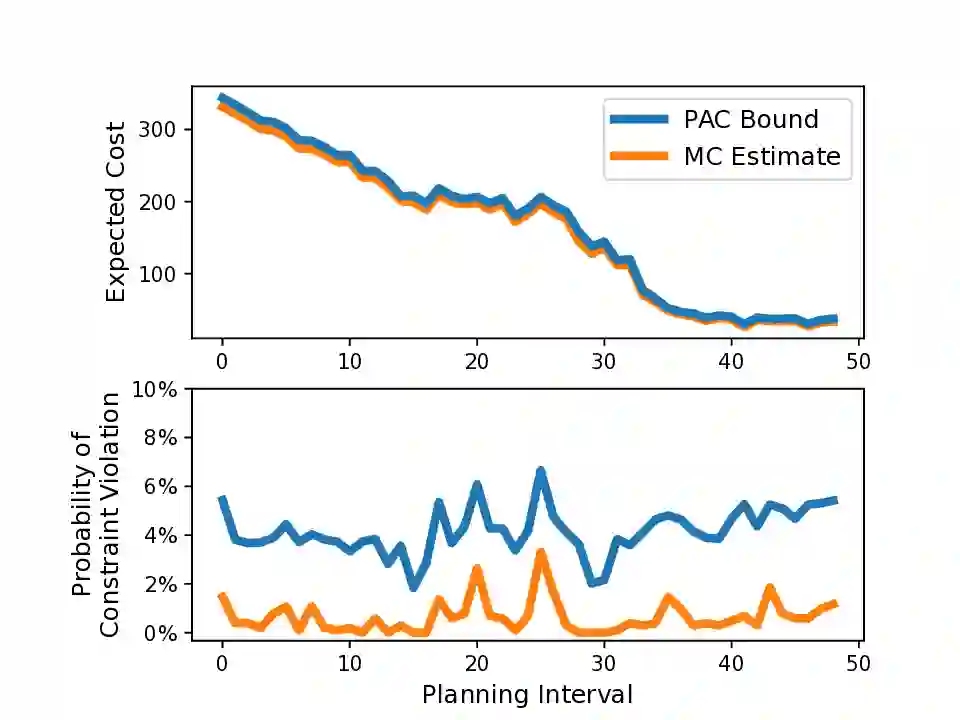
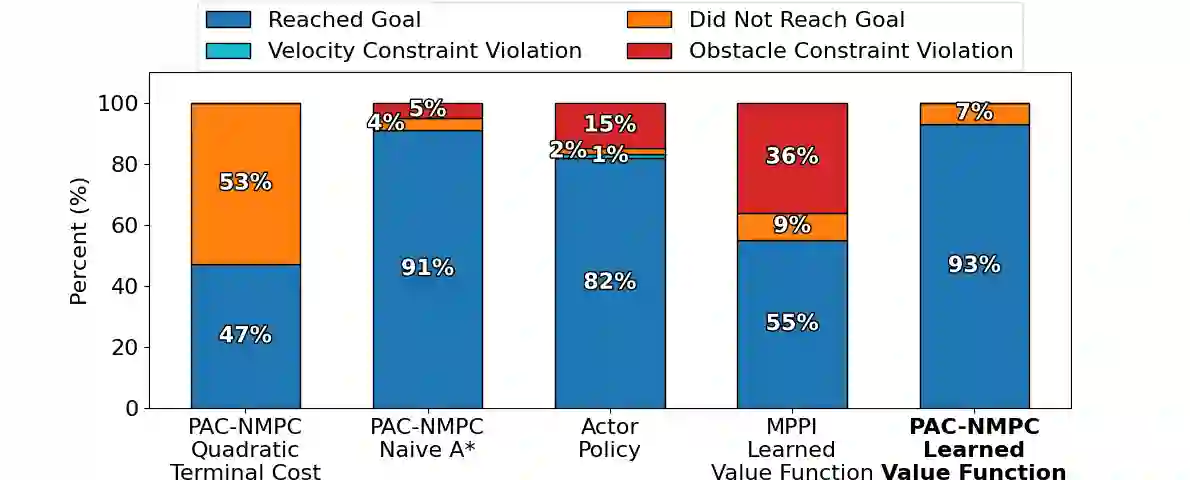
Nonlinear model predictive control (NMPC) is typically restricted to short, finite horizons to limit the computational burden of online optimization. As a result, global planning frameworks are frequently necessary to avoid local minima when using NMPC for navigation in complex environments. By contrast, reinforcement learning (RL) can generate policies that minimize the expected cost over an infinite-horizon and can often avoid local minima, even when operating only on current sensor measurements. However, these learned policies are usually unable to provide performance guarantees (e.g., on collision avoidance), especially when outside of the training distribution. In this paper, we augment Probably Approximately Correct NMPC (PAC-NMPC), a sampling-based stochastic NMPC algorithm capable of providing statistical guarantees of performance and safety, with an approximate perception-dependent value function trained via RL. We demonstrate in simulation that our algorithm can improve the long-term behavior of PAC-NMPC while outperforming other approaches with regards to safety for both planar car dynamics and more complex, high-dimensional fixed-wing aerial vehicle dynamics. We also demonstrate that, even when our value function is trained in simulation, our algorithm can successfully achieve statistically safe navigation on hardware using a 1/10th scale rally car in cluttered real-world environments using only current sensor information.
翻译:暂无翻译