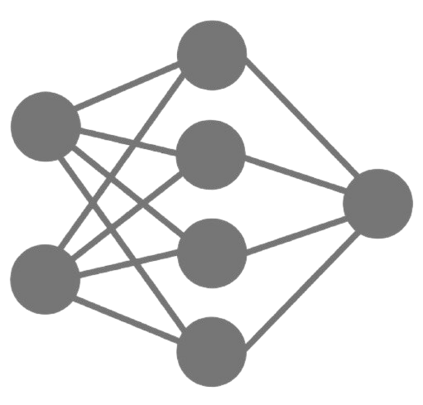
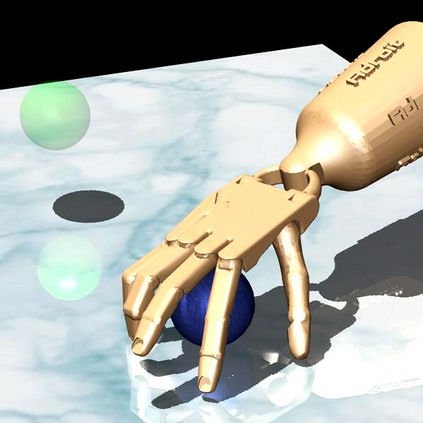
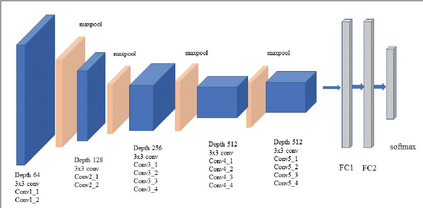
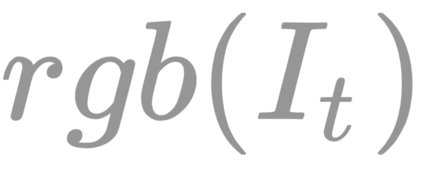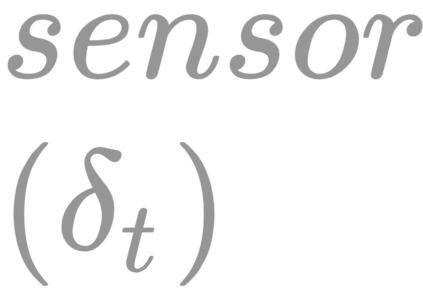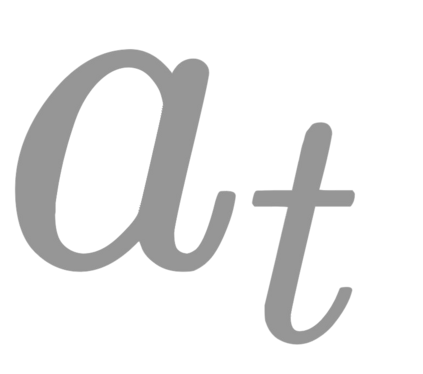The ability to autonomously learn behaviors via direct interactions in uninstrumented environments can lead to generalist robots capable of enhancing productivity or providing care in unstructured settings like homes. Such uninstrumented settings warrant operations only using the robot's proprioceptive sensor such as onboard cameras, joint encoders, etc which can be challenging for policy learning owing to the high dimensionality and partial observability issues. We propose RRL: Resnet as representation for Reinforcement Learning -- a straightforward yet effective approach that can learn complex behaviors directly from proprioceptive inputs. RRL fuses features extracted from pre-trained Resnet into the standard reinforcement learning pipeline and delivers results comparable to learning directly from the state. In a simulated dexterous manipulation benchmark, where the state of the art methods fail to make significant progress, RRL delivers contact rich behaviors. The appeal of RRL lies in its simplicity in bringing together progress from the fields of Representation Learning, Imitation Learning, and Reinforcement Learning. Its effectiveness in learning behaviors directly from visual inputs with performance and sample efficiency matching learning directly from the state, even in complex high dimensional domains, is far from obvious.
翻译:通过在非仪器环境中直接互动自主学习行为的能力,可能导致通用机器人能够提高生产力或为家庭等非结构化环境提供护理。这种未仪器设置只允许使用机器人自动感知传感器(如机载相机)、联合编码器等操作,由于高度的维度和部分的可观察性问题,这些传感器对政策学习具有挑战性。我们建议RRL:Resnet作为强化学习的代表,这是一种直接从自我认知投入中学习复杂行为的直截了当而有效的方法。RRL引信从预先训练的Resnet提取到标准强化学习管道,并提供与直接从州学习的类似的结果。在模拟的超模范操纵基准中,由于艺术方法的状态无法取得显著进展,RRRL提供接触丰富的行为。 RRL的吸引力在于将演示学习、吸收学习和强化学习领域的进展结合起来的简单性。RRRL在直接从视觉投入和样本效率中学习与从州直接从高空间直接学习的视觉输入和抽样学习行为的有效性方面,甚至在高度的复杂程度中是显而易见的。