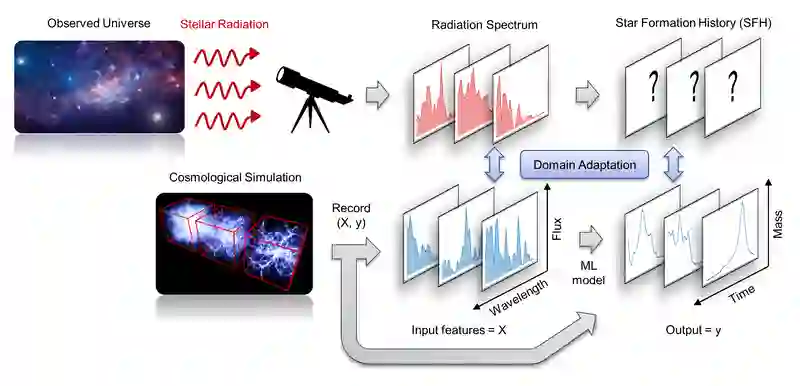
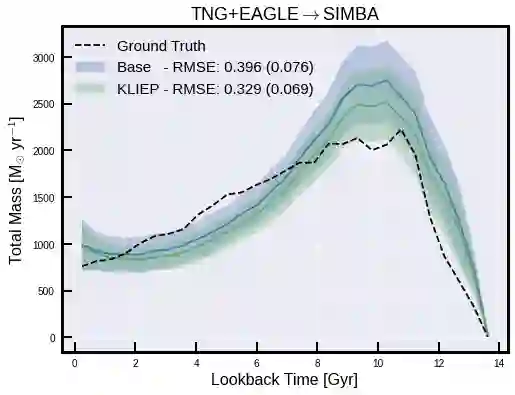
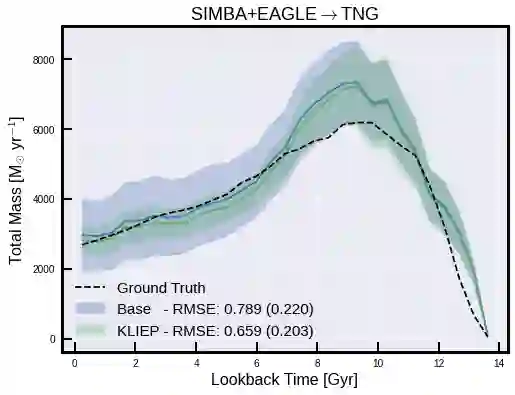
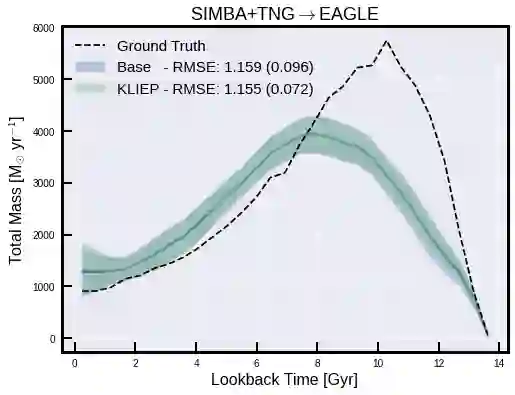
The prevalent paradigm of machine learning today is to use past observations to predict future ones. What if, however, we are interested in knowing the past given the present? This situation is indeed one that astronomers must contend with often. To understand the formation of our universe, we must derive the time evolution of the visible mass content of galaxies. However, to observe a complete star life, one would need to wait for one billion years! To overcome this difficulty, astrophysicists leverage supercomputers and evolve simulated models of galaxies till the current age of the universe, thus establishing a mapping between observed radiation and star formation histories (SFHs). Such ground-truth SFHs are lacking for actual galaxy observations, where they are usually inferred -- with often poor confidence -- from spectral energy distributions (SEDs) using Bayesian fitting methods. In this investigation, we discuss the ability of unsupervised domain adaptation to derive accurate SFHs for galaxies with simulated data as a necessary first step in developing a technique that can ultimately be applied to observational data.
翻译:今天,机器学习的典型模式是利用以往的观测来预测未来。然而,如果我们对了解过去感兴趣,因为目前的情况?这种情况确实是一个天文学家必须经常面对的情况。为了了解宇宙的形成,我们必须从星系可见质量内容的时间演变中得出一个完整的恒星生命期。然而,为了克服这一困难,天体物理学家需要等待10亿年的时间。为了克服这一困难,天体物理学家利用超级计算机,并进化到宇宙目前这个时代之前的模拟星系模型,从而在观测到的辐射和恒星形成史之间绘制地图。这种地壳的SFH在实际的星系观测中缺乏,而这种地壳通常 -- -- 往往缺乏信心 -- -- 利用Bayesian的装配方法从光谱能量分布中推断出来。在本次调查中,我们讨论了未经监控的域适应是否有能力用模拟数据获得精确的星系SFH,作为开发最终可用于观测数据的技术的必要的第一步。