
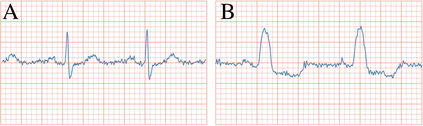
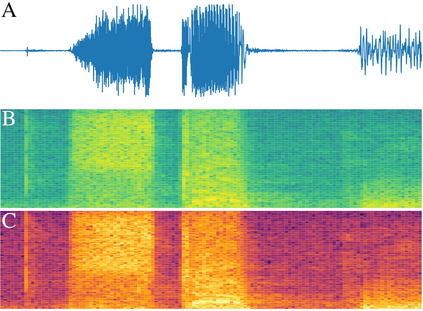
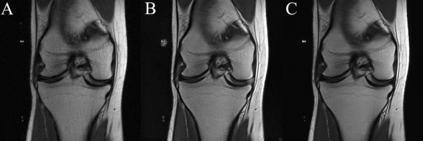
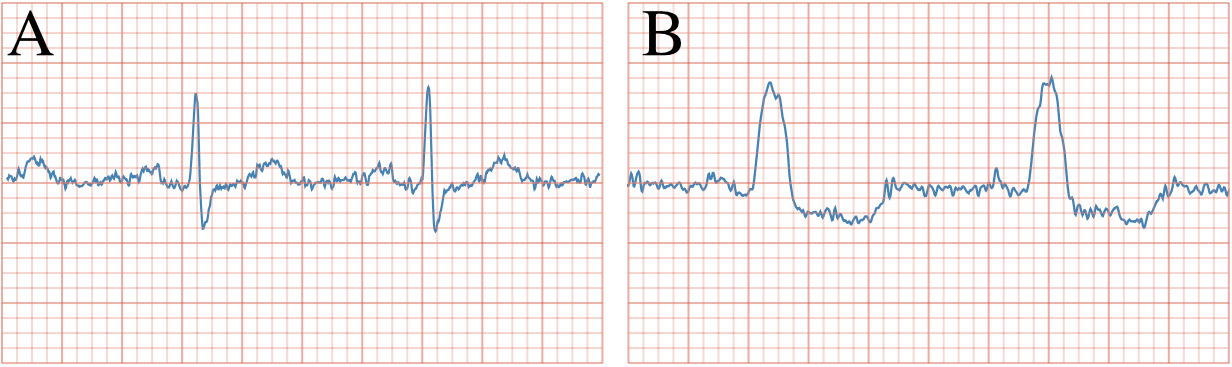
We present $\zeta$-DP, an extension of differential privacy (DP) to complex-valued functions. After introducing the complex Gaussian mechanism, whose properties we characterise in terms of $(\varepsilon, \delta)$-DP and R\'enyi-DP, we present $\zeta$-DP stochastic gradient descent ($\zeta$-DP-SGD), a variant of DP-SGD for training complex-valued neural networks. We experimentally evaluate $\zeta$-DP-SGD on three complex-valued tasks, i.e. electrocardiogram classification, speech classification and magnetic resonance imaging (MRI) reconstruction. Moreover, we provide $\zeta$-DP-SGD benchmarks for a large variety of complex-valued activation functions and on a complex-valued variant of the MNIST dataset. Our experiments demonstrate that DP training of complex-valued neural networks is possible with rigorous privacy guarantees and excellent utility.
翻译:我们提出美元-美元-DP,这是将差异隐私(DP)扩大至复杂价值的功能。在引入复杂的高山机制(我们以美元(varepsilon,\delta)美元-DP和R\'enyi-DP为特征)之后,我们提出美元-美元-DP的随机梯度(zeta$-DP-SGD),这是用于培训复杂价值的神经网络的DP-SGD的变种。我们试验性地评估了美元-美元-DP-SGD的三种复杂价值的工作,即电动心电图分类、语音分类和磁共振成成像(MRI)重建。此外,我们还为大量复杂价值的激活功能和MNIST数据集的复杂价值变种提供了美元-DP-SGD基准。我们的实验表明,DP对复杂价值的神经网络的培训在严格的隐私保障和极有用的情况下是可能的。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


