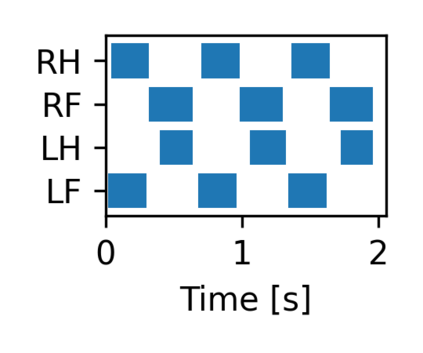
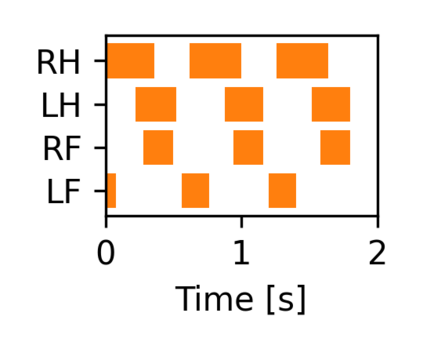
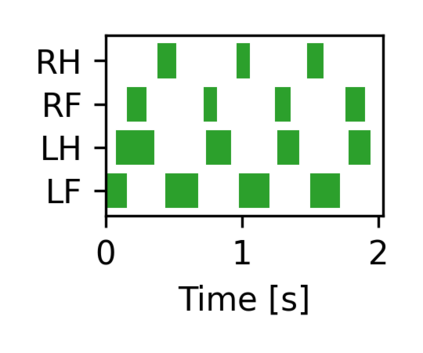
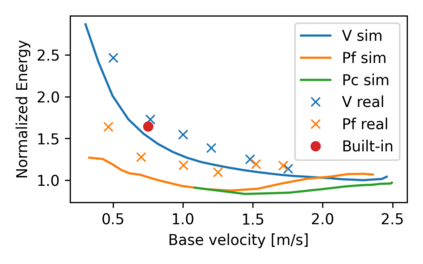
The common approach for local navigation on challenging environments with legged robots requires path planning, path following and locomotion, which usually requires a locomotion control policy that accurately tracks a commanded velocity. However, by breaking down the navigation problem into these sub-tasks, we limit the robot's capabilities since the individual tasks do not consider the full solution space. In this work, we propose to solve the complete problem by training an end-to-end policy with deep reinforcement learning. Instead of continuously tracking a precomputed path, the robot needs to reach a target position within a provided time. The task's success is only evaluated at the end of an episode, meaning that the policy does not need to reach the target as fast as possible. It is free to select its path and the locomotion gait. Training a policy in this way opens up a larger set of possible solutions, which allows the robot to learn more complex behaviors. We compare our approach to velocity tracking and additionally show that the time dependence of the task reward is critical to successfully learn these new behaviors. Finally, we demonstrate the successful deployment of policies on a real quadrupedal robot. The robot is able to cross challenging terrains, which were not possible previously, while using a more energy-efficient gait and achieving a higher success rate.
翻译:使用有腿的机器人,当地在具有挑战性的环境中对有腿的机器人进行本地导航的通用方法要求路径规划、路径跟踪和移动,通常需要一种精确跟踪定速速度的移动控制政策。然而,通过将导航问题分解到这些子任务中,我们限制机器人的能力,因为个别任务没有考虑完全的解决方案空间。在这项工作中,我们提议通过训练一个端对端政策,以深层强化学习来解决全部问题。我们比较我们采用的速度跟踪方法,并额外表明任务奖励的时间依赖性对于成功了解这些新行为至关重要。最后,我们证明在某一事件结束时,该任务的成功才需要评估,这意味着该政策不需要尽可能快地达到目标。可以自由选择其路径和移动轨迹。以这种方式培训一项政策可以打开更多可能的解决办法,使机器人能够学习更复杂的行为。我们比较了速度跟踪方法,并表明任务奖励对时间的依赖性对于成功学习这些新行为至关重要。最后,我们展示了在真实的四重的地形上成功部署政策,而机器人则能够实现更高的速度。