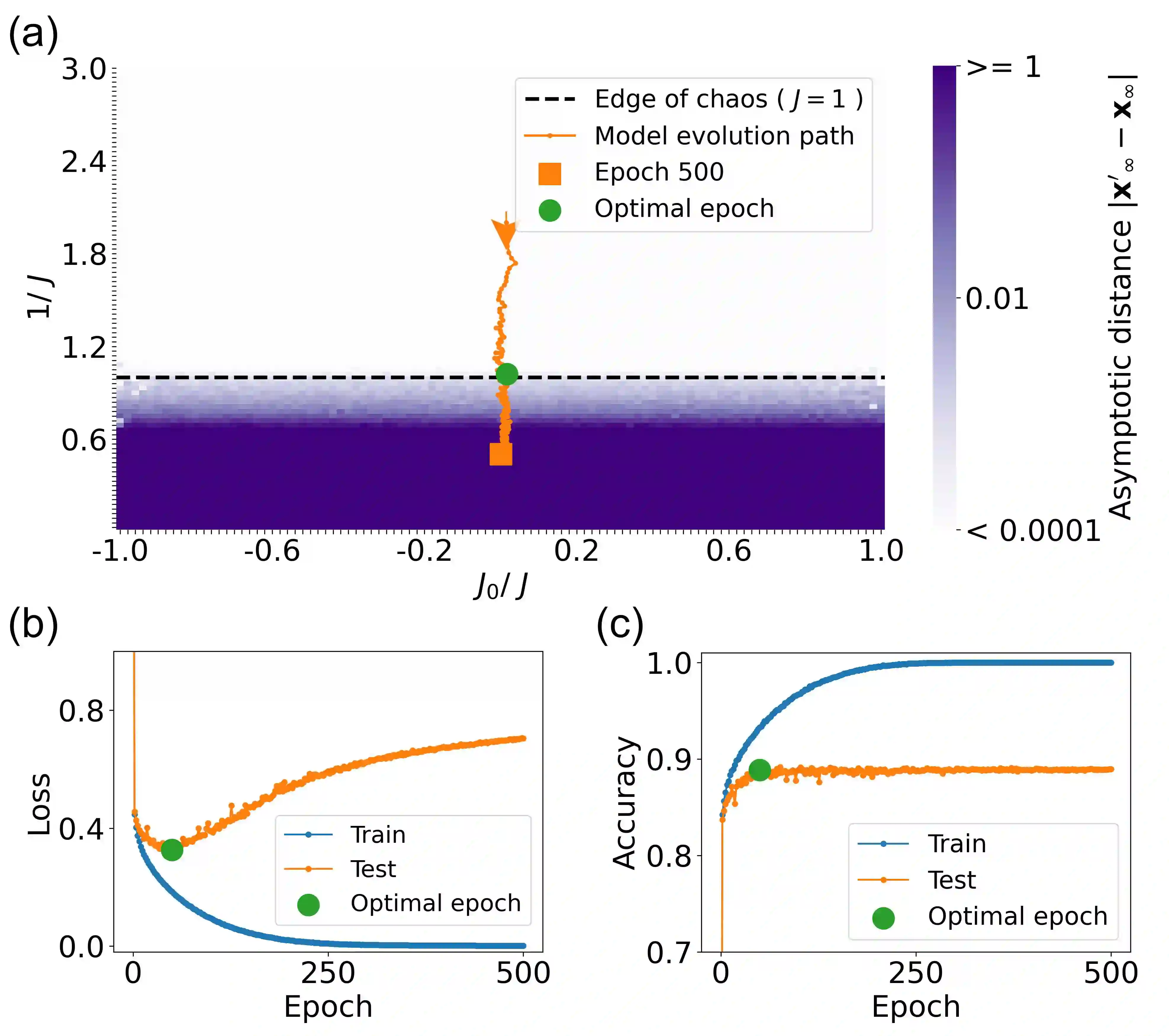
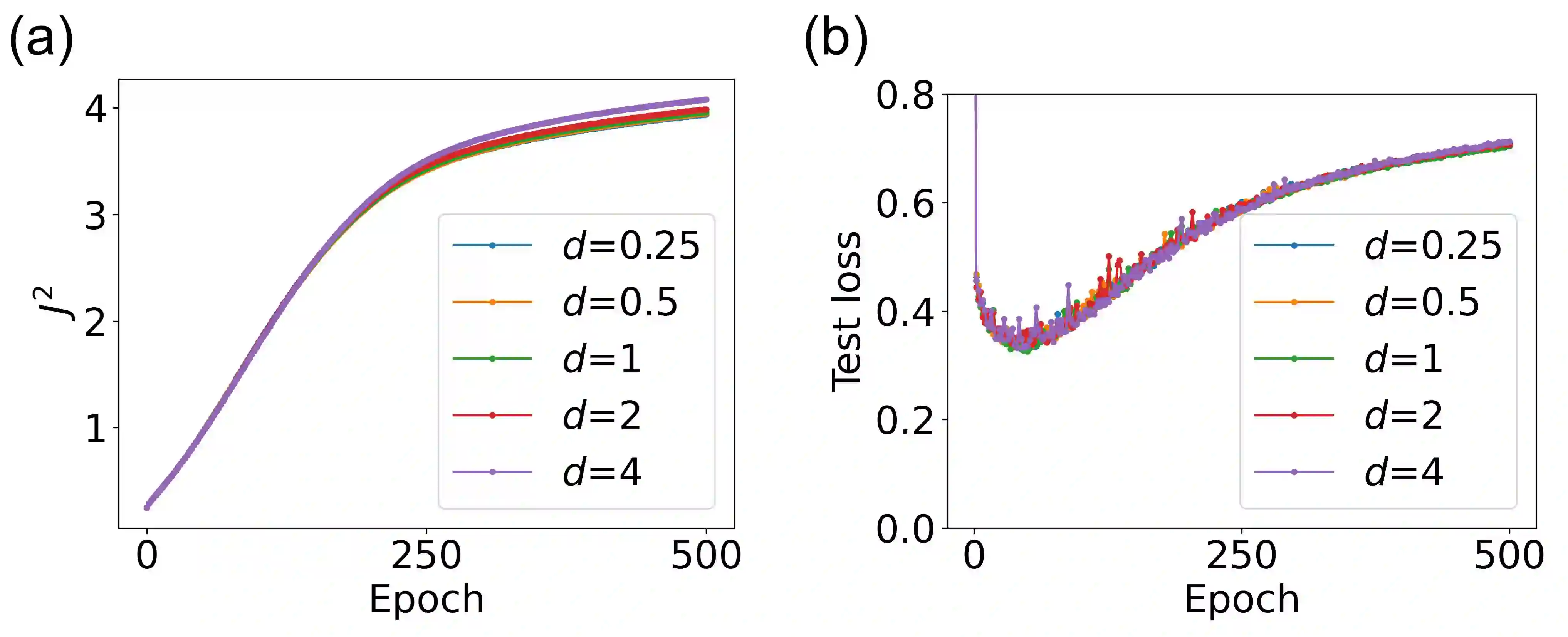
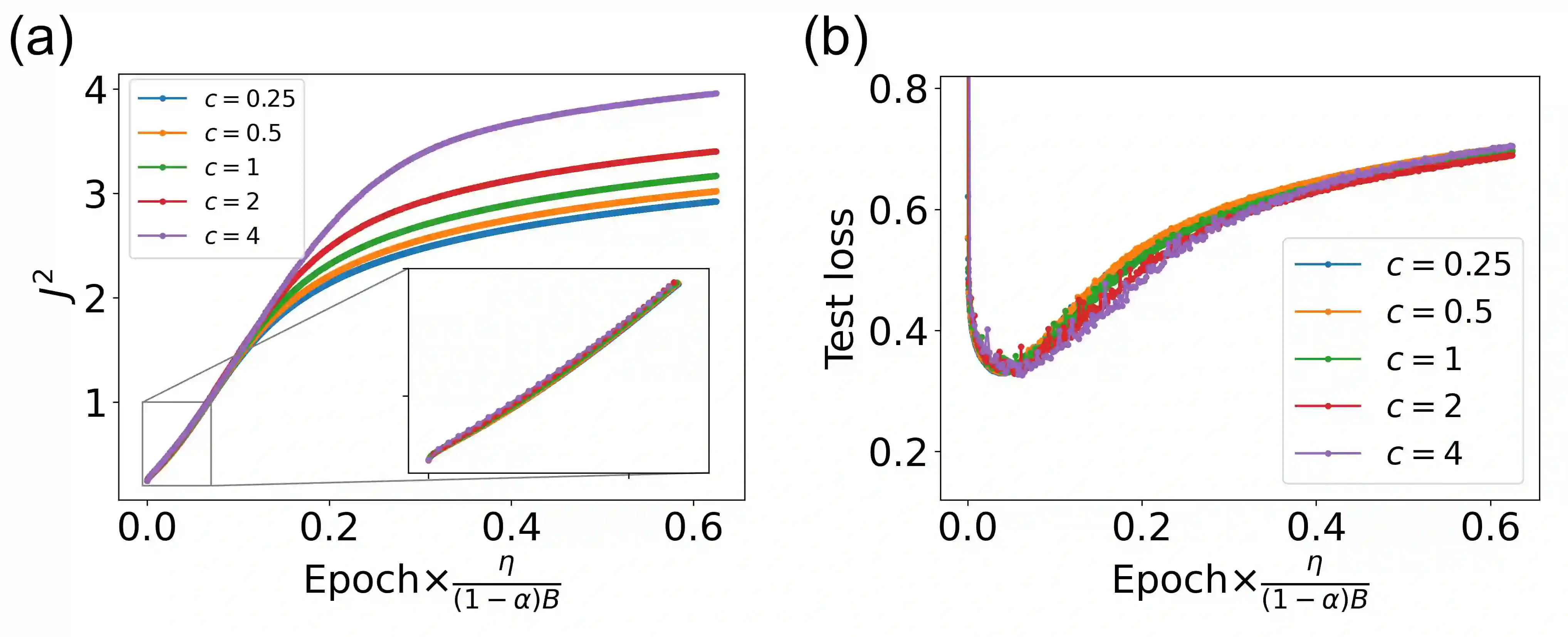
The success of deep neural networks in real-world problems has prompted many attempts to explain their training dynamics and generalization performance, but more guiding principles for the training of neural networks are still needed. Motivated by the edge of chaos principle behind the optimal performance of neural networks, we study the role of various hyperparameters in modern neural network training algorithms in terms of the order-chaos phase diagram. In particular, we study a fully analytical feedforward neural network trained on the widely adopted Fashion-MNIST dataset, and study the dynamics associated with the hyperparameters in back-propagation during the training process. We find that for the basic algorithm of stochastic gradient descent with momentum, in the range around the commonly used hyperparameter values, clear scaling relations are present with respect to the training time during the ordered phase in the phase diagram, and the model's optimal generalization power at the edge of chaos is similar across different training parameter combinations. In the chaotic phase, the same scaling no longer exists. The scaling allows us to choose the training parameters to achieve faster training without sacrificing performance. In addition, we find that the commonly used model regularization method - weight decay - effectively pushes the model towards the ordered phase to achieve better performance. Leveraging on this fact and the scaling relations in the other hyperparameters, we derived a principled guideline for hyperparameter determination, such that the model can achieve optimal performance by saturating it at the edge of chaos. Demonstrated on this simple neural network model and training algorithm, our work improves the understanding of neural network training dynamics, and can potentially be extended to guiding principles of more complex model architectures and algorithms.
翻译:在现实世界问题中深层神经网络的成功促使人们多次试图解释其培训动态和总体性效,但还需要有更多的培训神经网络的指导原则。我们受神经网络最佳性能背后混乱原则的边缘的驱动,研究现代神经网络培训算法中各种超光谱的作用。特别是,我们研究一个完全分析性的进化神经网络,在广泛采用的Fashion-MNIST数据集方面进行了培训,并研究与培训过程中后回演法中超参数相关的动态。我们发现,在通常使用的超光速值网络的最佳性能下沉的基本算法中,我们研究的是各种超光谱神经网络在命令阶段的神经网络培训算法中的角色。特别是,我们研究一个完全分析性的进化神经网络网络网络,从不同的模型模型模型模型组合中,可以使用同样的进化性能。在结构混乱阶段,这种规模的扩大使得我们选择培训参数,在不牺牲性能指导性能的情况下实现更快的培训模型。此外,我们发现,在普通的性能阶段里,我们使用的方法可以有效地调整,在更精确的模型中,从而实现更精确的变压。