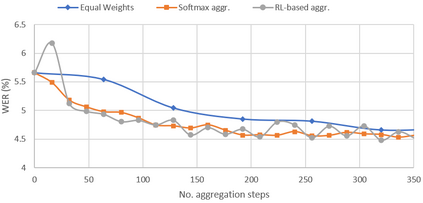
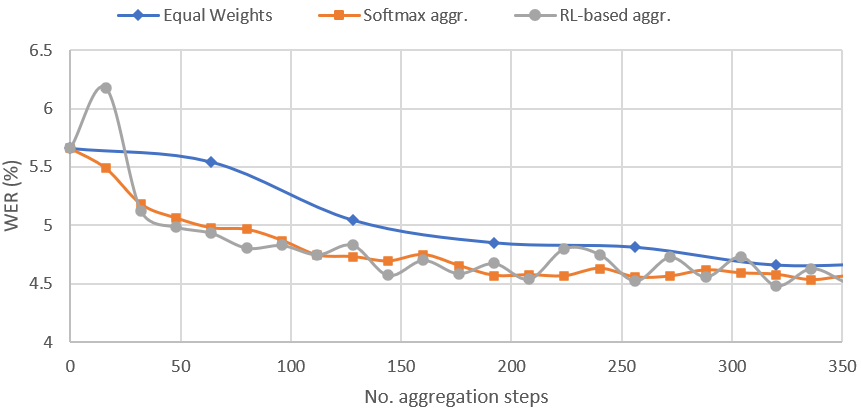
In this paper, a new learning algorithm for Federated Learning (FL) is introduced. The proposed scheme is based on a weighted gradient aggregation using two-step optimization to offer a flexible training pipeline. Herein, two different flavors of the aggregation method are presented, leading to an order of magnitude improvement in convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. Further, the aggregation algorithm acts as a regularizer of the gradient quality. We investigate the effect of our FL algorithm in supervised and unsupervised Speech Recognition (SR) scenarios. The experimental validation is performed based on three tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% word error rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing 20% WERR over a powerful LAS model. Finally, our unsupervised pipeline is applied to the conversational SR task. The proposed FL system outperforms the baseline systems in both convergence speed and overall model performance.
翻译:在本文中,引入了联邦学习联盟(FL)的新学习算法。拟议办法的基础是使用两步优化的加权梯度汇总,以提供一个灵活的培训管道。在此,提出了两种不同的组合方法口味,导致与其他分布式或FL培训算法(如BMUF和FedAvg)相比,趋同速度有一定的提高。此外,聚合算法作为梯度质量的正规化器发挥作用。我们调查了我们的FL算法在监督和不受监督的语音识别(SR)情景中的影响。实验验证基于三项任务进行:首先,LibriSpeech任务显示比基线结果加速7x和6%字差率降低(WERR),第二项任务基于会议调整,在强大的LAS模型上提供20%的WERR。最后,我们未受监督的管道用于谈话式的SR任务。拟议的FL系统在趋同速度和总体模型性能上都超过了基线系统。