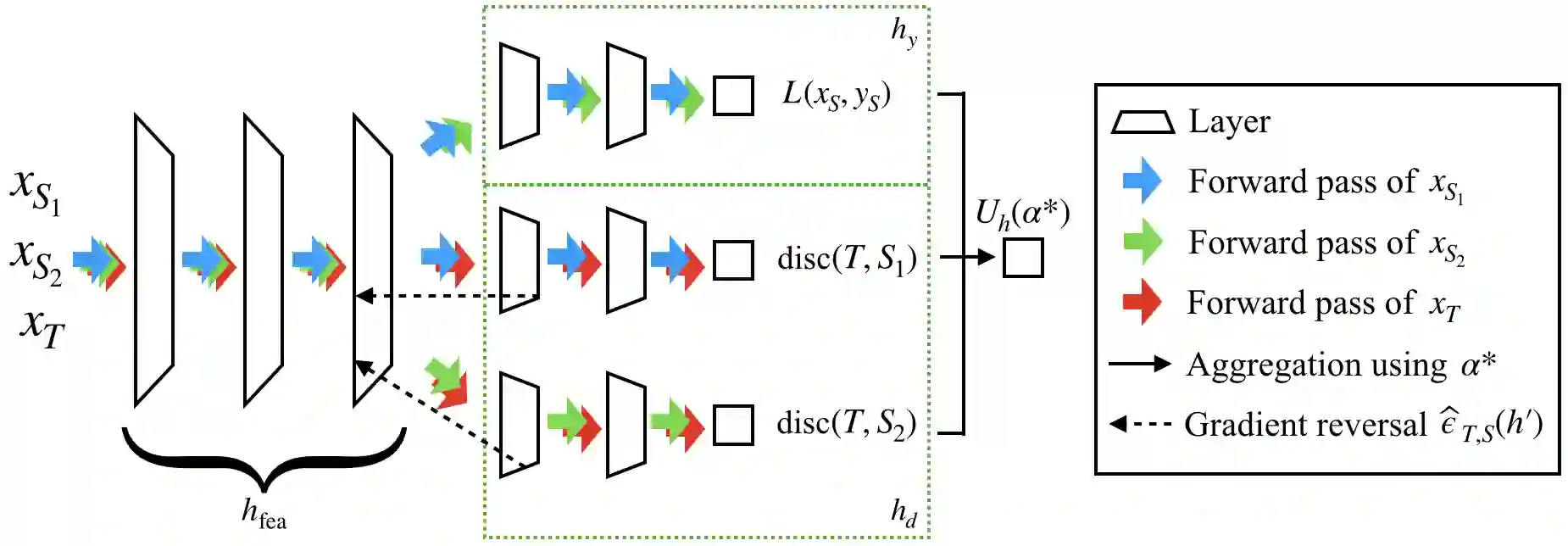
In many real-world applications, we want to exploit multiple source datasets of similar tasks to learn a model for a different but related target dataset -- e.g., recognizing characters of a new font using a set of different fonts. While most recent research has considered ad-hoc combination rules to address this problem, we extend previous work on domain discrepancy minimization to develop a finite-sample generalization bound, and accordingly propose a theoretically justified optimization procedure. The algorithm we develop, Domain AggRegation Network (DARN), is able to effectively adjust the weight of each source domain during training to ensure relevant domains are given more importance for adaptation. We evaluate the proposed method on real-world sentiment analysis and digit recognition datasets and show that DARN can significantly outperform the state-of-the-art alternatives.
翻译:在许多现实世界应用中,我们希望利用类似任务的多个源数据集学习不同但相关的目标数据集的模式 -- -- 例如,利用一组不同字体识别新字体的字符。虽然最近的研究已经审议了解决这一问题的特设组合规则,但我们扩大了以往关于域差异最小化的工作,以开发一个有限分布式的集成约束,并因此提出一个理论上合理的优化程序。我们开发的算法“Dmain AggRegation Net网络(DARN)”能够在培训中有效调整每个源域的权重,以确保相关领域对适应更加重要。我们评估了关于现实世界情绪分析和数字识别数据集的拟议方法,并表明DARN能够大大超越最新替代方法。