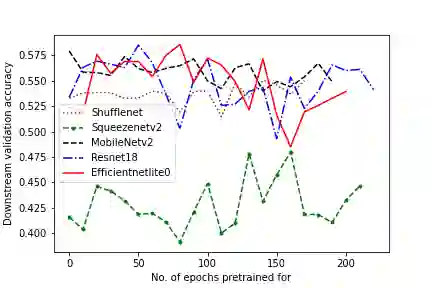
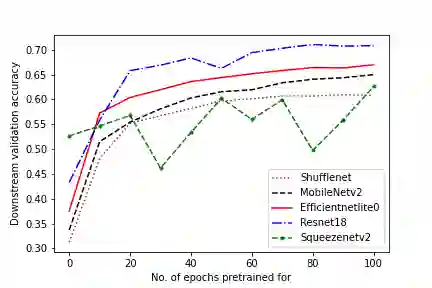
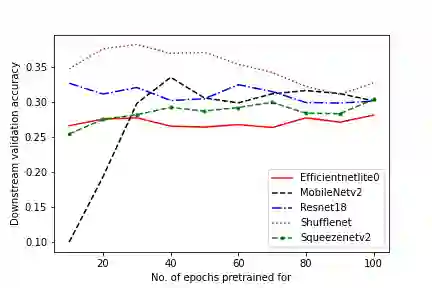
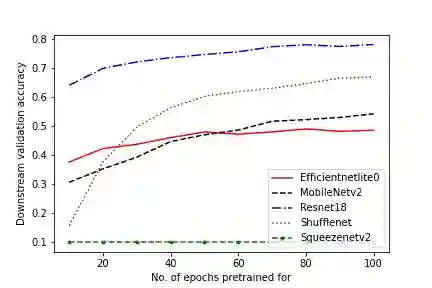
In self-supervised learning, a model is trained to solve a pretext task, using a data set whose annotations are created by a machine. The objective is to transfer the trained weights to perform a downstream task in the target domain. We critically examine the most notable pretext tasks to extract features from image data and further go on to conduct experiments on resource constrained networks, which aid faster experimentation and deployment. We study the performance of various self-supervised techniques keeping all other parameters uniform. We study the patterns that emerge by varying model type, size and amount of pre-training done for the backbone as well as establish a standard to compare against for future research. We also conduct comprehensive studies to understand the quality of representations learned by different architectures.
翻译:在自我监督的学习中,利用机器制作说明的数据集,对模型进行解决托辞任务的培训,目的是转让经过训练的重量,以便在目标领域执行下游任务;我们严格审查从图像数据中提取特征的最显著的托辞任务,并进一步对资源有限的网络进行实验,这有助于更快的试验和部署;我们研究各种自我监督技术的性能,使所有其他参数保持统一;我们研究骨干训练前的型号、规模和数量各不相同的格局,并制订与未来研究进行比较的标准;我们还进行全面研究,以了解不同结构所学会的表述质量。