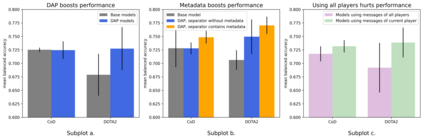
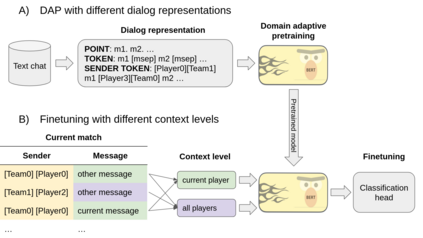
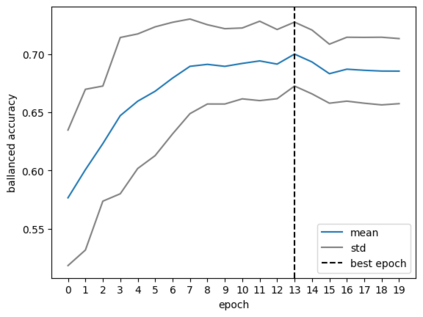
The detrimental effects of toxicity in competitive online video games are widely acknowledged, prompting publishers to monitor player chat conversations. This is challenging due to the context-dependent nature of toxicity, often spread across multiple messages or informed by non-textual interactions. Traditional toxicity detectors focus on isolated messages, missing the broader context needed for accurate moderation. This is especially problematic in video games, where interactions involve specialized slang, abbreviations, and typos, making it difficult for standard models to detect toxicity, especially given its rarity. We adapted RoBERTa LLM to support moderation tailored to video games, integrating both textual and non-textual context. By enhancing pretrained embeddings with metadata and addressing the unique slang and language quirks through domain adaptive pretraining, our method better captures the nuances of player interactions. Using two gaming datasets - from Defense of the Ancients 2 (DOTA 2) and Call of Duty$^\circledR$: Modern Warfare$^\circledR$III (MWIII) we demonstrate which sources of context (metadata, prior interactions...) are most useful, how to best leverage them to boost performance, and the conditions conducive to doing so. This work underscores the importance of context-aware and domain-specific approaches for proactive moderation.
翻译:暂无翻译