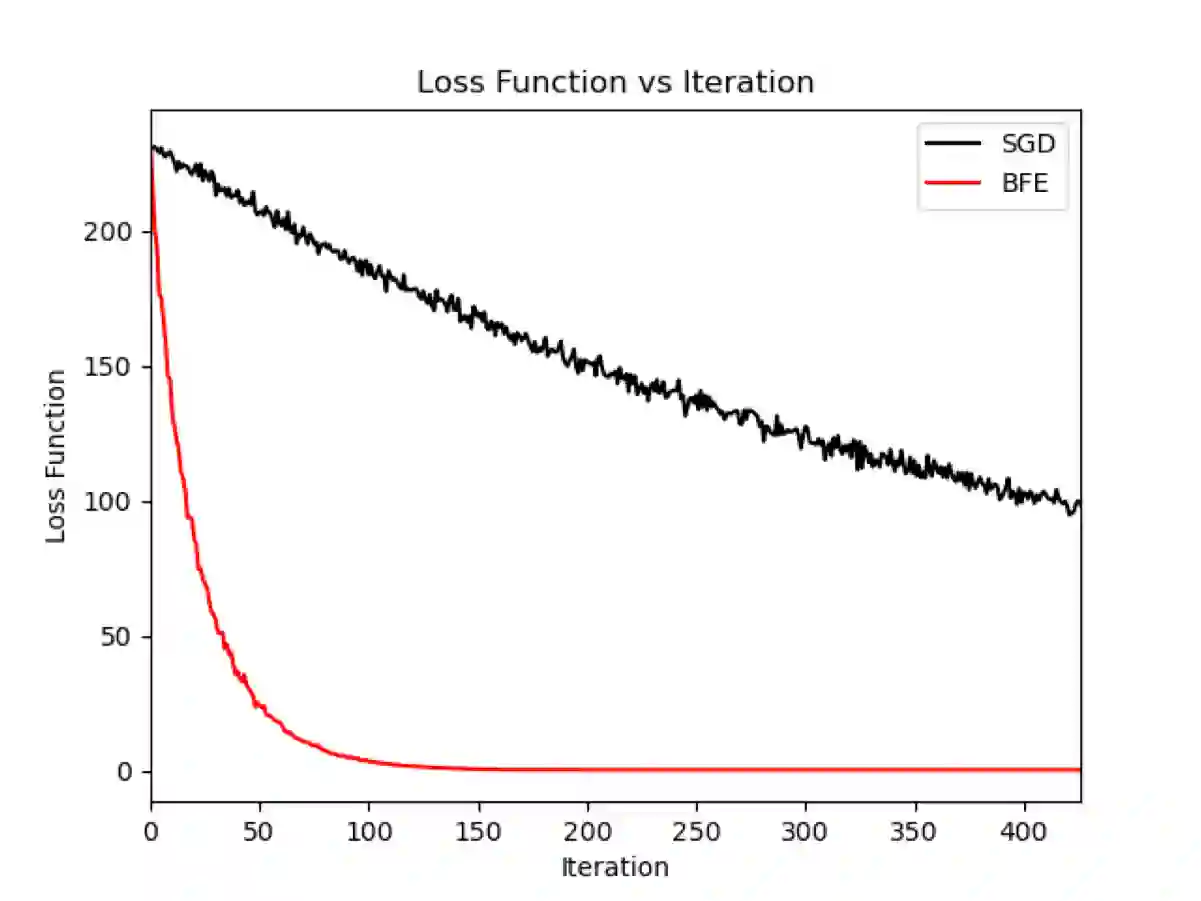
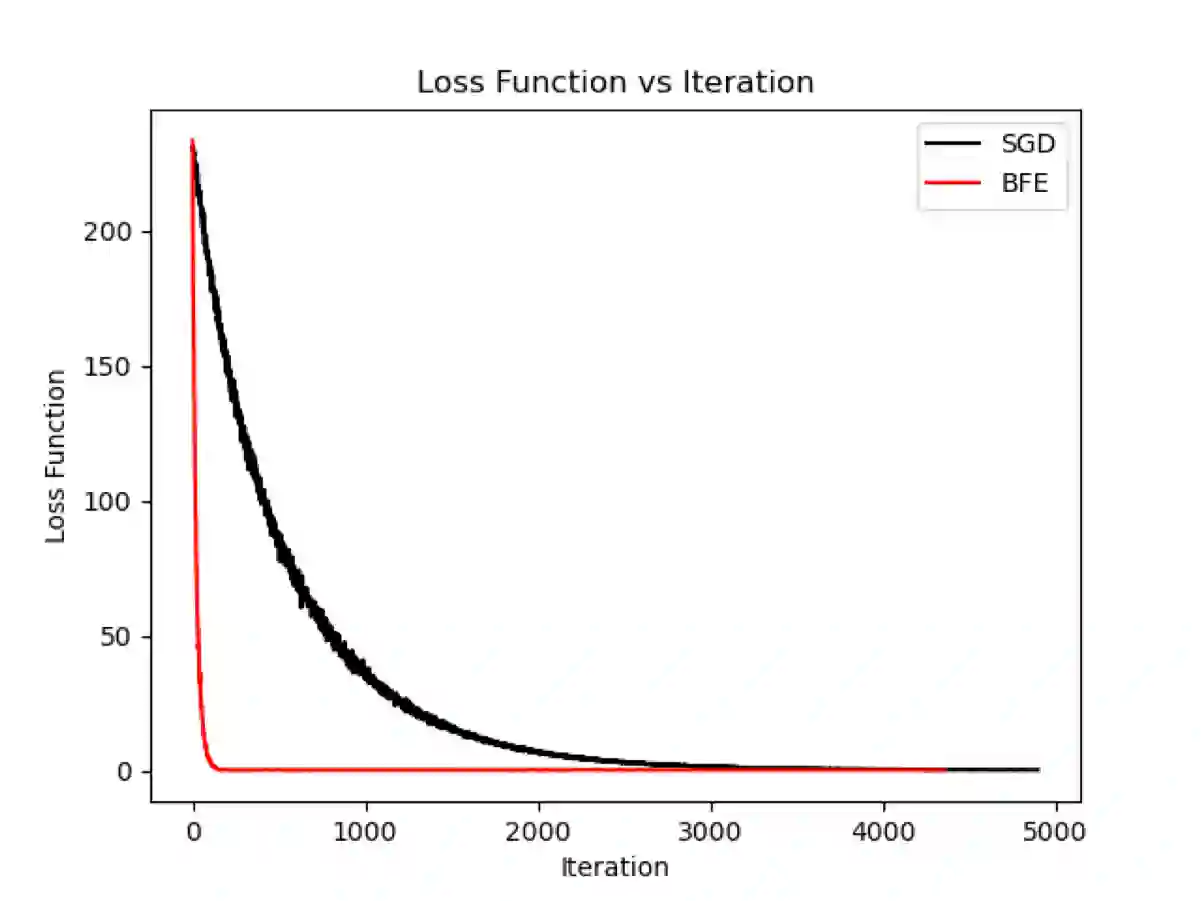
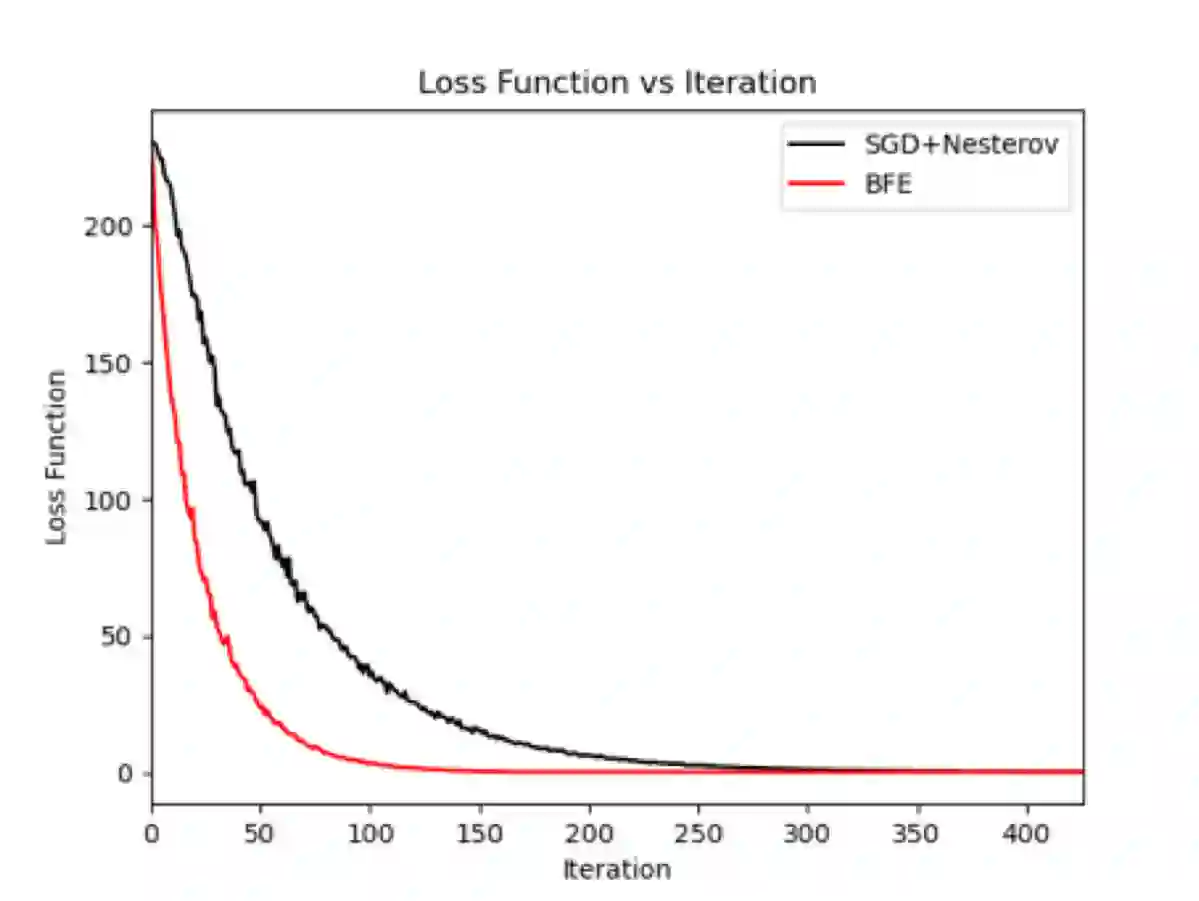
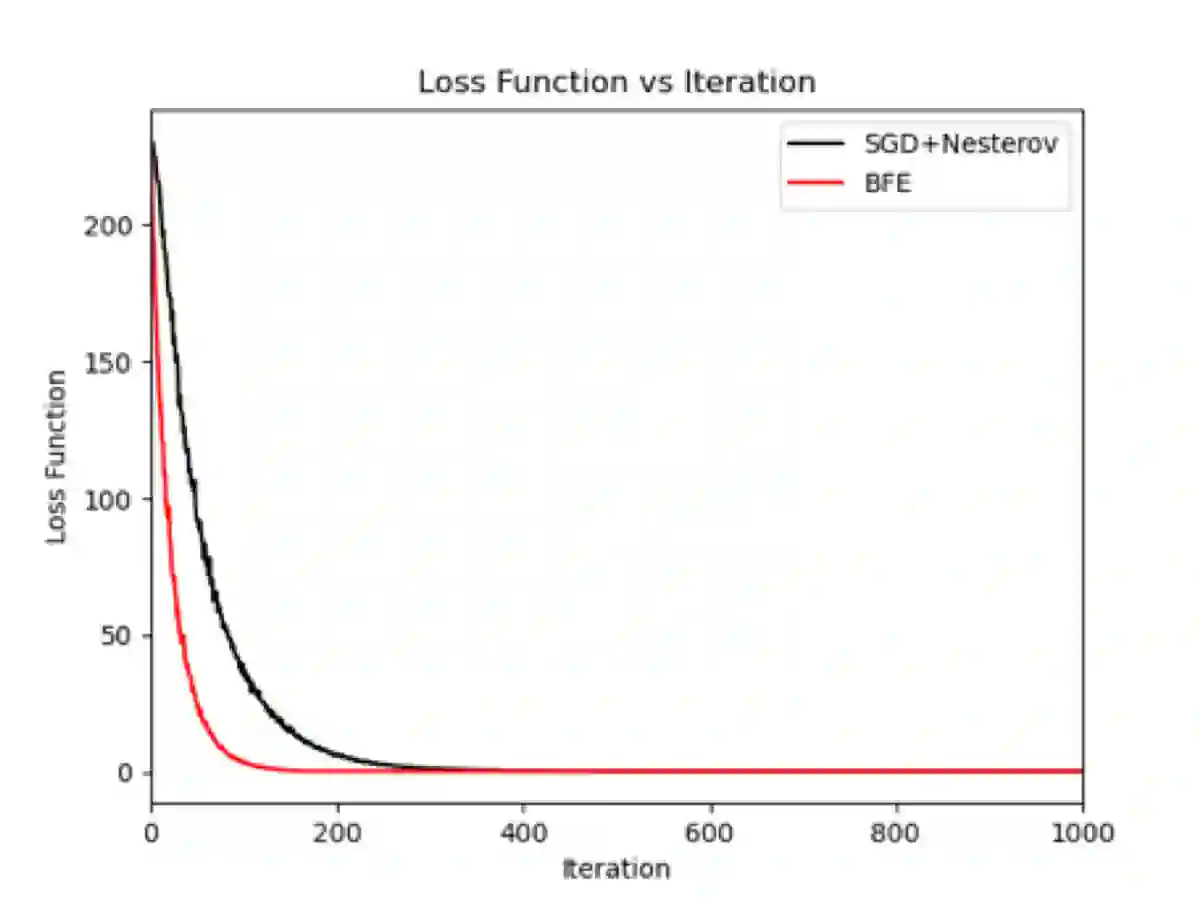
In this paper, a new gradient-based optimization approach by automatically adjusting the learning rate is proposed. This approach can be applied to design non-adaptive learning rate and adaptive learning rate. Firstly, I will introduce the non-adaptive learning rate optimization method: Binary Forward Exploration (BFE), and then the corresponding adaptive per-parameter learning rate method: Adaptive BFE (AdaBFE) is possible to be developed. This approach could be an alternative method to optimize the learning rate based on the stochastic gradient descent (SGD) algorithm besides the current non-adaptive learning rate methods e.g. SGD, momentum, Nesterov and the adaptive learning rate methods e.g. AdaGrad, AdaDelta, Adam... The purpose to develop this approach is not to beat the benchmark of other methods but just to provide a different perspective to optimize the gradient descent method, although some comparative study with previous methods will be made in the following sections. This approach is expected to be heuristic or inspire researchers to improve gradient-based optimization combined with previous methods.
翻译:在本文中,提出了通过自动调整学习率的新的梯度优化方法。 这种方法可以适用于设计非适应性学习率和适应性学习率。 首先, 我将采用非适应性学习率优化方法: 二进式前瞻性探索(BFE), 然后是相应的适应性单数学习率方法: 有可能开发适应性BFE(AdaBFE) 。 这种方法可以是一种替代方法, 优化基于随机性梯度下沉算法(SGD) 的学习率。 除了目前的非适应性学习率方法(如SGD)、 动力、 Nesterov 和适应性学习率方法(如AdaGrad、AdaDelta、Adam)之外, 。 制定这一方法的目的不是要超越其他方法的基准,而只是为了提供一个不同的观点来优化梯度下降法, 尽管与以往方法的一些比较研究将在以下各节中进行。 这种方法预计将是超额研究或激励研究人员改进梯度优化与以往方法相结合的梯度方法。