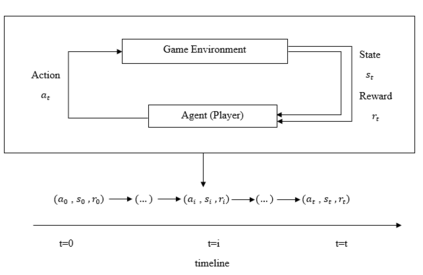
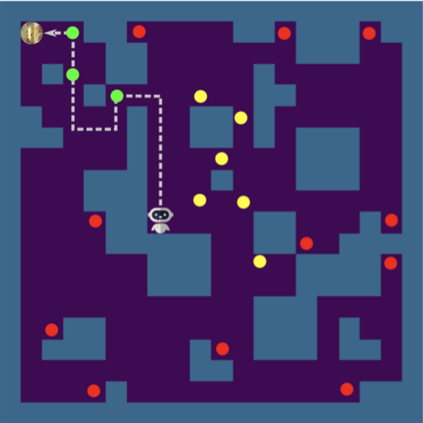
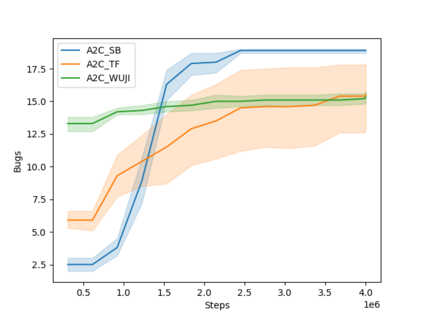
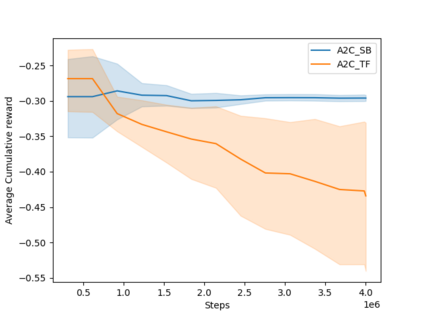
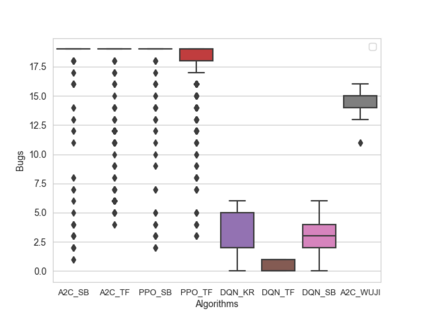
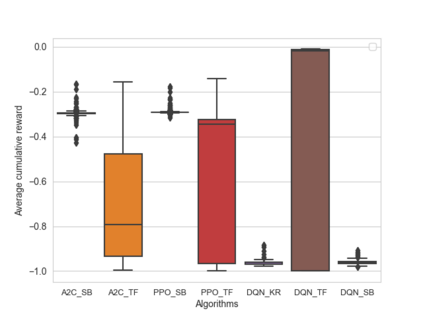
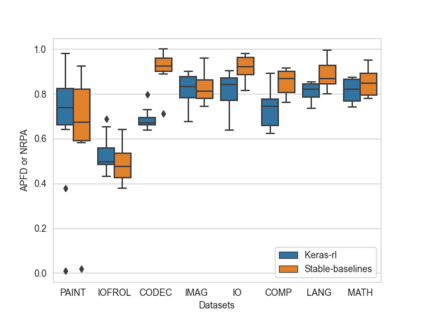
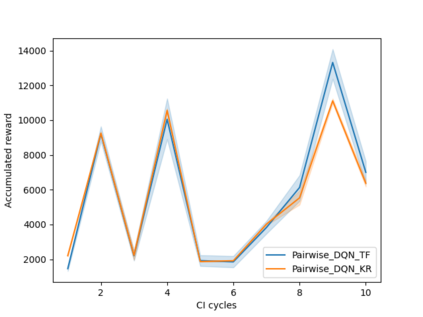
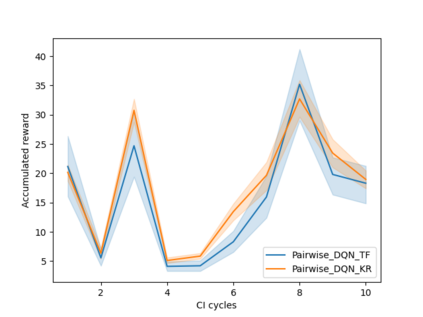
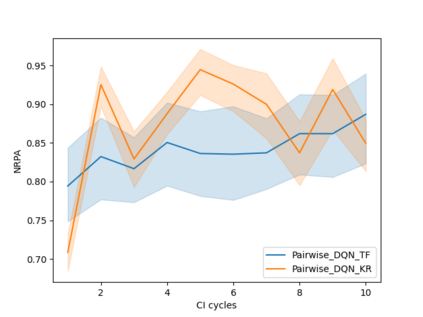
Software testing activities aim to find the possible defects of a software product and ensure that the product meets its expected requirements. Some software testing approached are lacking automation or are partly automated which increases the testing time and overall software testing costs. Recently, Reinforcement Learning (RL) has been successfully employed in complex testing tasks such as game testing, regression testing, and test case prioritization to automate the process and provide continuous adaptation. Practitioners can employ RL by implementing from scratch an RL algorithm or use an RL framework. Developers have widely used these frameworks to solve problems in various domains including software testing. However, to the best of our knowledge, there is no study that empirically evaluates the effectiveness and performance of pre-implemented algorithms in RL frameworks. In this paper, we empirically investigate the applications of carefully selected RL algorithms on two important software testing tasks: test case prioritization in the context of Continuous Integration (CI) and game testing. For the game testing task, we conduct experiments on a simple game and use RL algorithms to explore the game to detect bugs. Results show that some of the selected RL frameworks such as Tensorforce outperform recent approaches in the literature. To prioritize test cases, we run experiments on a CI environment where RL algorithms from different frameworks are used to rank the test cases. Our results show that the performance difference between pre-implemented algorithms in some cases is considerable, motivating further investigation. Moreover, empirical evaluations on some benchmark problems are recommended for researchers looking to select RL frameworks, to make sure that RL algorithms perform as intended.
翻译:软件测试活动旨在找出软件产品可能存在的缺陷,并确保产品符合预期要求。一些软件测试缺乏自动化,或者部分自动化,增加了测试时间和软件测试总成本。最近,在游戏测试、回归测试和测试案件优先排序等复杂测试任务中成功运用了强化学习(RL),使程序自动化并不断调整。从业者可以通过从零开始实施RL算法或使用RL框架来使用RL。开发者广泛使用这些框架来解决包括软件测试在内的不同领域的问题。然而,据我们所知,没有一项实验性研究能够评估RL框架中预先实施的算法的有效性和性能。在本文中,我们通过实验性地调查,在连续整合(CI)和游戏测试中测试案件优先进行案件优先排序。关于游戏测试任务,我们用RL算法来进一步探索各种领域的问题,包括软件测试错误。但结果显示,一些选定的RL框架,如Tersorforce在RL框架中评估效力和性评估,在最新性评估中,我们测试案例中,我们用VL逻辑测试了一定的排序。