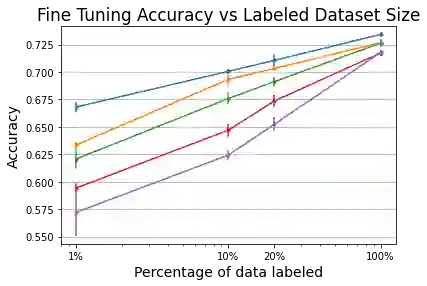
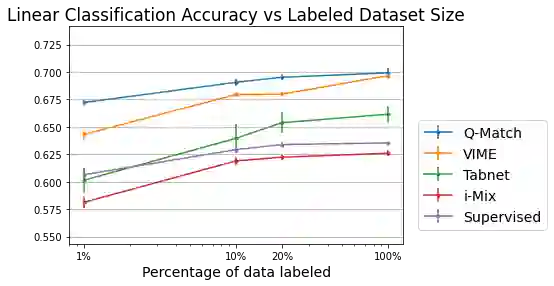
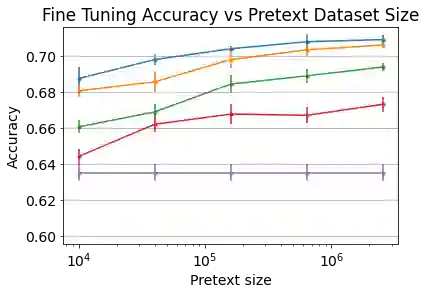
In semi-supervised learning, student-teacher distribution matching has been successful in improving performance of models using unlabeled data in conjunction with few labeled samples. In this paper, we aim to replicate that success in the self-supervised setup where we do not have access to any labeled data during pre-training. We introduce our algorithm, Q-Match, and show it is possible to induce the student-teacher distributions without any knowledge of downstream classes by using a queue of embeddings of samples from the unlabeled dataset. We focus our study on tabular datasets and show that Q-Match outperforms previous self-supervised learning techniques when measuring downstream classification performance. Furthermore, we show that our method is sample efficient--in terms of both the labels required for downstream training and the amount of unlabeled data required for pre-training--and scales well to the sizes of both the labeled and unlabeled data.
翻译:在半监督的学习中,师生分布比对成功地改善了模型使用未贴标签的数据以及少数标签样本的性能。 在本文中,我们的目标是在自我监督的设置中复制这一成功,因为我们在培训前无法取得任何标签数据。 我们引入了我们的算法Q-Match, 并展示了通过使用未贴标签数据集样本嵌入队列来诱导教师在不了解下游等级的情况下进行教师分配的可能性。 我们的研究侧重于表格数据集,并显示在测量下游分类性能时,Q-Match优于以前自我监督的学习技术。 此外,我们展示了我们的方法是,在下游培训所需的标签以及培训前和规模所需的未贴标签数据数量方面,都非常符合标签和未贴标签数据的规模。