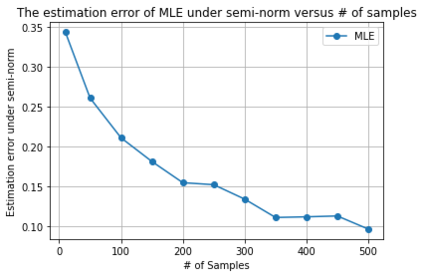
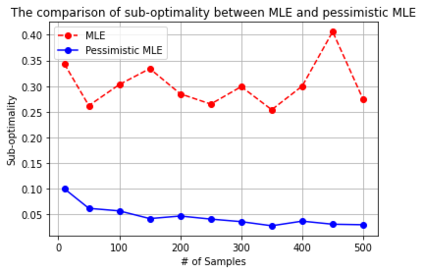
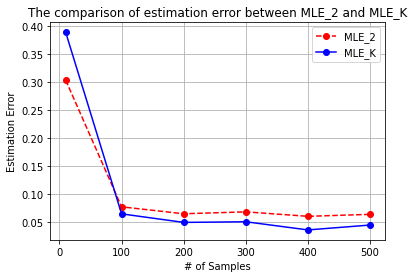
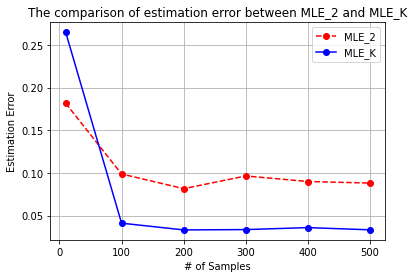
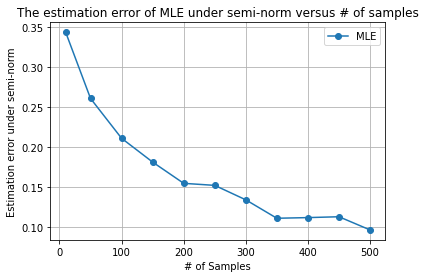
We provide a theoretical framework for Reinforcement Learning with Human Feedback (RLHF). Our analysis shows that when the true reward function is linear, the widely used maximum likelihood estimator (MLE) converges under both the Bradley-Terry-Luce (BTL) model and the Plackett-Luce (PL) model. However, we show that when training a policy based on the learned reward model, MLE fails while a pessimistic MLE provides policies with improved performance under certain coverage assumptions. Additionally, we demonstrate that under the PL model, the true MLE and an alternative MLE that splits the $K$-wise comparison into pairwise comparisons both converge. Moreover, the true MLE is asymptotically more efficient. Our results validate the empirical success of existing RLHF algorithms in InstructGPT and provide new insights for algorithm design. Furthermore, our results unify the problem of RLHF and max-entropy Inverse Reinforcement Learning (IRL), and provide the first sample complexity bound for max-entropy IRL.
翻译:我们的分析表明,当真正的奖励功能是线性时,广泛使用的最大可能性估测器(MLE)在布拉德利-泰瑞-卢斯(BTL)模式和普拉基特-卢斯(PL)模式下会合。然而,我们表明,在根据学习的奖励模式培训一项政策时,MLE失败,而悲观的MLE则在某些覆盖假设下提供业绩改进的政策。此外,我们证明,在PL模式下,真正的MLE和替代的MLE,将美元对齐比较分成一。此外,真实的MLEE效率同样高。我们的结果验证了现有RLHF算法在指令GPT方面的实证成功,并为算法设计提供了新的洞察力。此外,我们的结果统一了RLHF和最高偏偏偏加强学习(IRL)问题,并提供了以最大吸附的IRL为约束的第一样本复杂性。