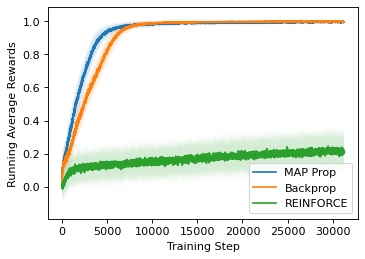
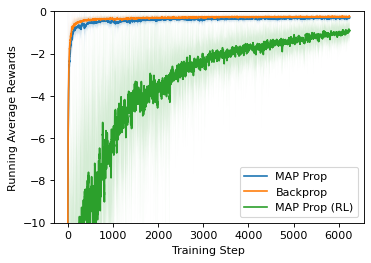
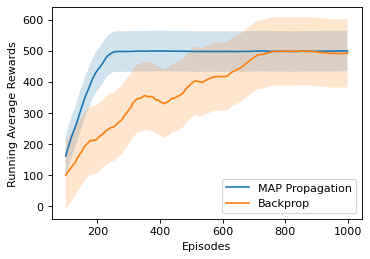
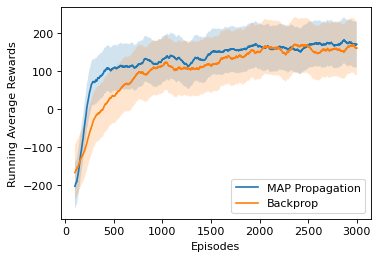
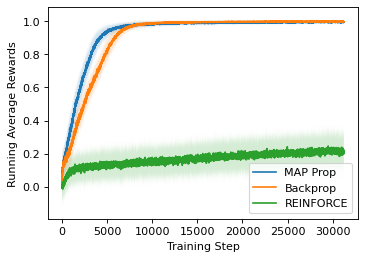
State-of-the-art deep learning algorithms mostly rely on gradient backpropagation to train a deep artificial neural network, which is generally regarded to be biologically implausible. For a network of stochastic units trained on a reinforcement learning task or a supervised learning task, one biologically plausible way of learning is to train each unit by REINFORCE. In this case, only a global reward signal has to be broadcast to all units, and the learning rule given is local, which can be interpreted as reward-modulated spike-timing-dependent plasticity (R-STDP) that is observed biologically. Although this learning rule follows the gradient of return in expectation, it suffers from high variance and cannot be used to train a deep network in practice. In this paper, we propose an algorithm called MAP propagation that can reduce this variance significantly while retaining the local property of learning rule. Different from prior works on local learning rules (e.g. Contrastive Divergence) which mostly applies to undirected models in unsupervised learning tasks, our proposed algorithm applies to directed models in reinforcement learning tasks. We show that the newly proposed algorithm can solve common reinforcement learning tasks at a speed similar to that of backpropagation when applied to an actor-critic network.
翻译:最先进的深层次学习算法大多依赖梯度回路变换法来训练深层人工神经网络,通常认为这种神经网络在生物学上是难以置信的。对于一个受过强化学习任务或监督学习任务训练的随机单元网络来说,一种生物学上可行的学习方式就是由REINFORCE来训练每个单元。在这个案例中,只有全球奖励信号才需要向所有单元广播,而所提供的学习规则是当地性的,这可以被解释为在生物学上观测到的奖励性调制悬浮依赖性塑料(R-STDP),虽然这种学习规则遵循回报的梯度,但它存在很大的差异,无法用于在实践上训练深层次的网络。在这个文件中,我们建议一种叫作MAP传播的算法,可以大大减少这种差异,同时保留当地学习规则的特性。不同于以前关于地方学习规则的工作(例如对比性变异性变异性),它通常适用于非定向的模型,在不统一学习任务中,我们提议的算法适用于在强化学习任务时指导模型。我们表明,新提议的演算法可以加强新的演算系统,在学习速度时可以解决共同任务。