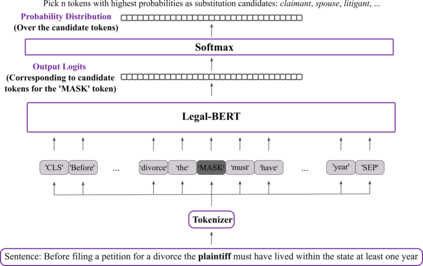
The processing of legal texts has been developing as an emerging field in natural language processing (NLP). Legal texts contain unique jargon and complex linguistic attributes in vocabulary, semantics, syntax, and morphology. Therefore, the development of text simplification (TS) methods specific to the legal domain is of paramount importance for facilitating comprehension of legal text by ordinary people and providing inputs to high-level models for mainstream legal NLP applications. While a recent study proposed a rule-based TS method for legal text, learning-based TS in the legal domain has not been considered previously. Here we introduce an unsupervised simplification method for legal texts (USLT). USLT performs domain-specific TS by replacing complex words and splitting long sentences. To this end, USLT detects complex words in a sentence, generates candidates via a masked-transformer model, and selects a candidate for substitution based on a rank score. Afterward, USLT recursively decomposes long sentences into a hierarchy of shorter core and context sentences while preserving semantic meaning. We demonstrate that USLT outperforms state-of-the-art domain-general TS methods in text simplicity while keeping the semantics intact.
翻译:法律文本的处理是自然语言处理(NLP)的一个新兴领域。法律文本在词汇、语义、语法和形态学中包含独特的术语和复杂的语言特征。因此,制定法律领域特有的文本简化方法对于便利普通人理解法律文本和为主流法律文本应用的高层次模式提供投入至关重要。最近的一项研究为法律文本提出了一个基于规则的TS方法,而法律领域的基于学习的TS在法律领域却从未被考虑过。我们在这里对法律文本采用了一种不受监督的简化方法(USLT)。美国LT通过替换复杂的单词和分解长句来进行具体领域的TS。为此,美国LT在句中发现复杂的单词,通过蒙面的变换模式产生候选人,并选择一个按等级分替换的候选人。之后,美国LT在保留语义含义的同时,将长句从一个较短的核心和上引出。我们证明,美国LTT在保持S-S的简单性时,将S-main-marital 方法置于州-sistrictral-stal-stal-simpal-tal-trmals。